最终编辑版本发表于:《自然》。2024年7月;631(8019):142–149。doi:10.1038/s41586-024-07578-8。
原文下载:https://fb.biokingdom.top/f/6a8e24c8c3d24b539deb/
¶ 脑嵌合体揭示个体对神经毒性触发因素的易感性
诺埃莉亚·安东-博拉尼奥斯1,2,#、伊雷妮·法拉韦利1,2,#、泰勒·费茨1,2,3、索菲亚·安德烈亚迪斯1、拉赫尔·卡斯特利1,2、塞巴斯蒂亚诺·特拉塔罗1,2、贤·阿迪科尼斯2,3、安琪·魏1,2、阿布舍克·萨帕斯·库马尔1,2、丹妮拉·J·迪贝拉1,2、马修·泰特迈尔1,2、拉尔达·内梅1,2、约书亚·Z·莱文2,3、阿维夫·雷格夫4,5、保拉·阿洛塔1,2,*
1.哈佛大学干细胞与再生生物学系,美国马萨诸塞州剑桥市
2.斯坦利精神病学研究中心,麻省理工学院和哈佛大学博德研究所,剑桥,马萨诸塞州,美国
3.克拉曼细胞Ob 天文台,麻省理工学院和哈佛大学的布罗德研究所,剑桥 ,马萨诸塞州,美国
麻省理工学院和哈佛大学布罗德研究所,美国马萨诸塞州波士顿
基因泰克公司,南旧金山,加州,美国
¶ 总结段落
个体间的遗传变异会影响许多疾病的易感性和进展进程。然而,由于缺乏可靠的人类细胞模型,且现有体系难以扩展至多样本表征,关于个体大脑在正常发育和疾病表型中差异性的研究始终受限。本文提出的人类大脑"嵌合体"——一种通过多位个体供体细胞在单类器官内共同发育形成的高重现性、多供体人脑皮质类器官模型,有效解决了这一难题。该模型通过对神经干细胞或神经前体阶段的多供体单类器官细胞进行重聚集,在祖细胞阶段,我们培育出嵌合体类器官,其中每个供体均可生成大脑皮质的所有细胞谱系——即使使用的是具有显著生长偏好的多能干细胞系。我们利用该模型研究了个体对神经毒性触发因素易感性的差异,这些因素在临床上表现出高度的表型变异性:乙醇和抗癫痫药物丙戊酸。不同供体在靶细胞类型效应外显率及受累细胞类型的分子表型方面均存在差异。研究结果表明,人类遗传背景可能是神经毒素易感性的重要介质,同时确立了嵌合体类器官作为可扩展系统,用于高通量研究大脑发育与疾病进程中的个体差异。
¶ 引言
遗传变异在疾病触发因素的差异性易感性中起着关键作用{1,2}。然而,尽管个体易感性的效应可在体外系统中被检测到{1,3–5},但由于既忠实于内源性人类生物学、又能在多人规模上应用的实验模型有限,对其机制的探索仍面临阻碍。
在大脑研究领域,开创性研究已对多能干细胞(PSC)衍生的二维神经元培养体系进行改良,建立了包含多个供体细胞系的大规模群体模型6-11。然而,二维培养系统通常只能产生有限范围的细胞类型,无法反映内源性大脑的多样性。三维细胞培养模型(如人脑类器官)则能更精准地模拟内源性大脑的细胞复杂性及发育过程。将"培养皿村落"{v*}研究模式10,11拓展至三维类器官培养的尝试始终受限,因为生长速率差异和分化偏向在类器官系统中尤为突出——这类系统需要多种细胞类型在长期培养过程中协同发育8。预先筛选生长速率匹配的多能干细胞系可缓解此问题11,但会将实验设计局限在相容的细胞系组合内。
在此,我们展示三维多供体嵌合体:一种高度可重复的人类皮质类器官模型,该模型能保持不同供体间细胞类型的均衡代表性,且无需预先筛选多能干细胞系。我们运用该模型测量了个体对两种神经毒性应激源发育暴露的易感性差异:乙醇(与胎儿酒精综合征相关12)以及抗癫痫药物丙戊酸(与自闭症谱系障碍风险升高相关13,14)。在嵌合体模型中,乙醇和丙戊酸均引发了多种细胞类型的变化,更重要的是,该模型成功捕捉到不同供体对毒性反应的特异性差异。总体而言,我们的研究结果表明:个体间差异会显著影响对神经毒性触发因素的易感性,而嵌合体可作为可扩展平台,用于测量不同人类个体脑细胞生物反应的变异程度。
¶ 大脑嵌合体产生跨个体供体平衡分布的皮质细胞多样性
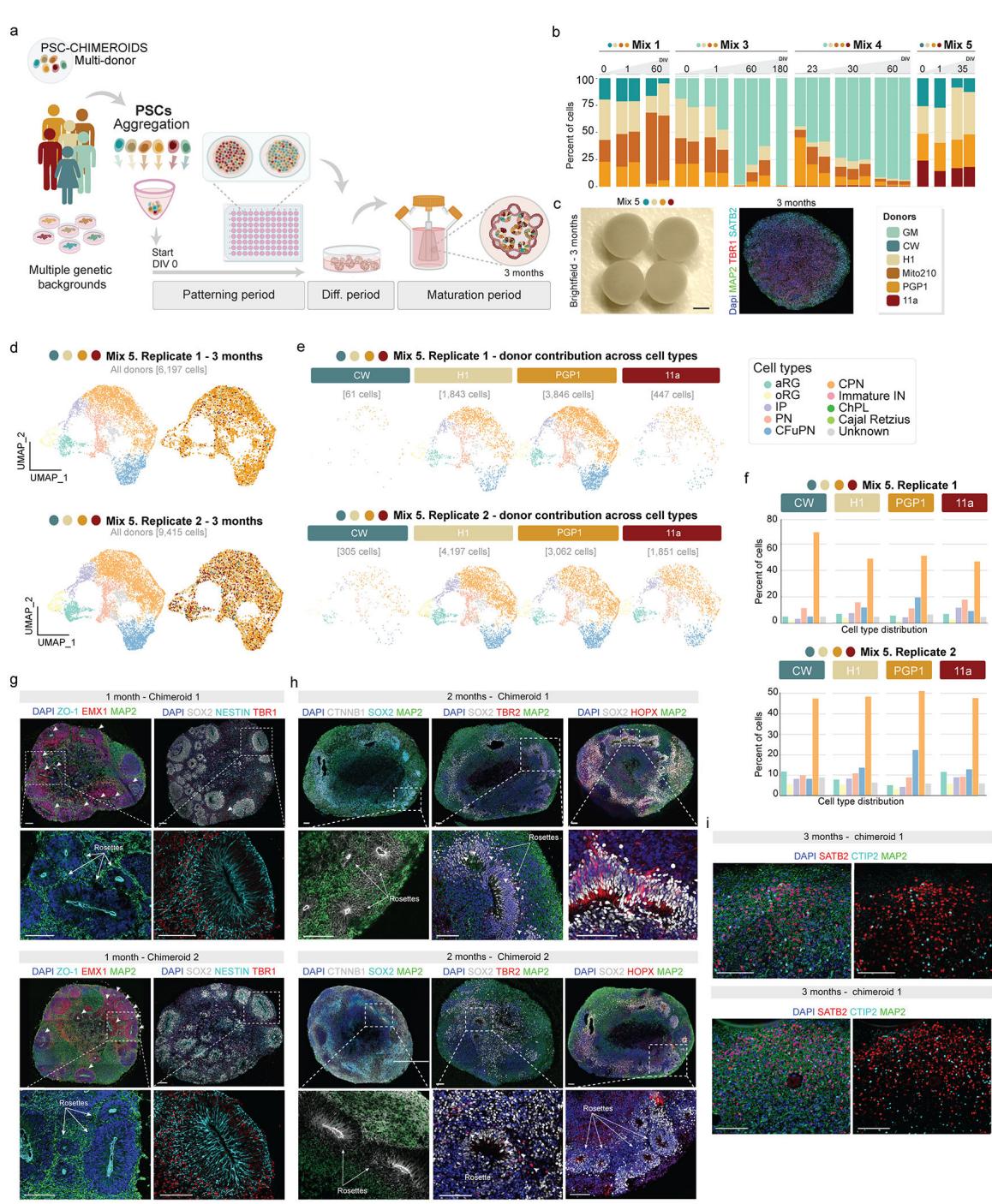
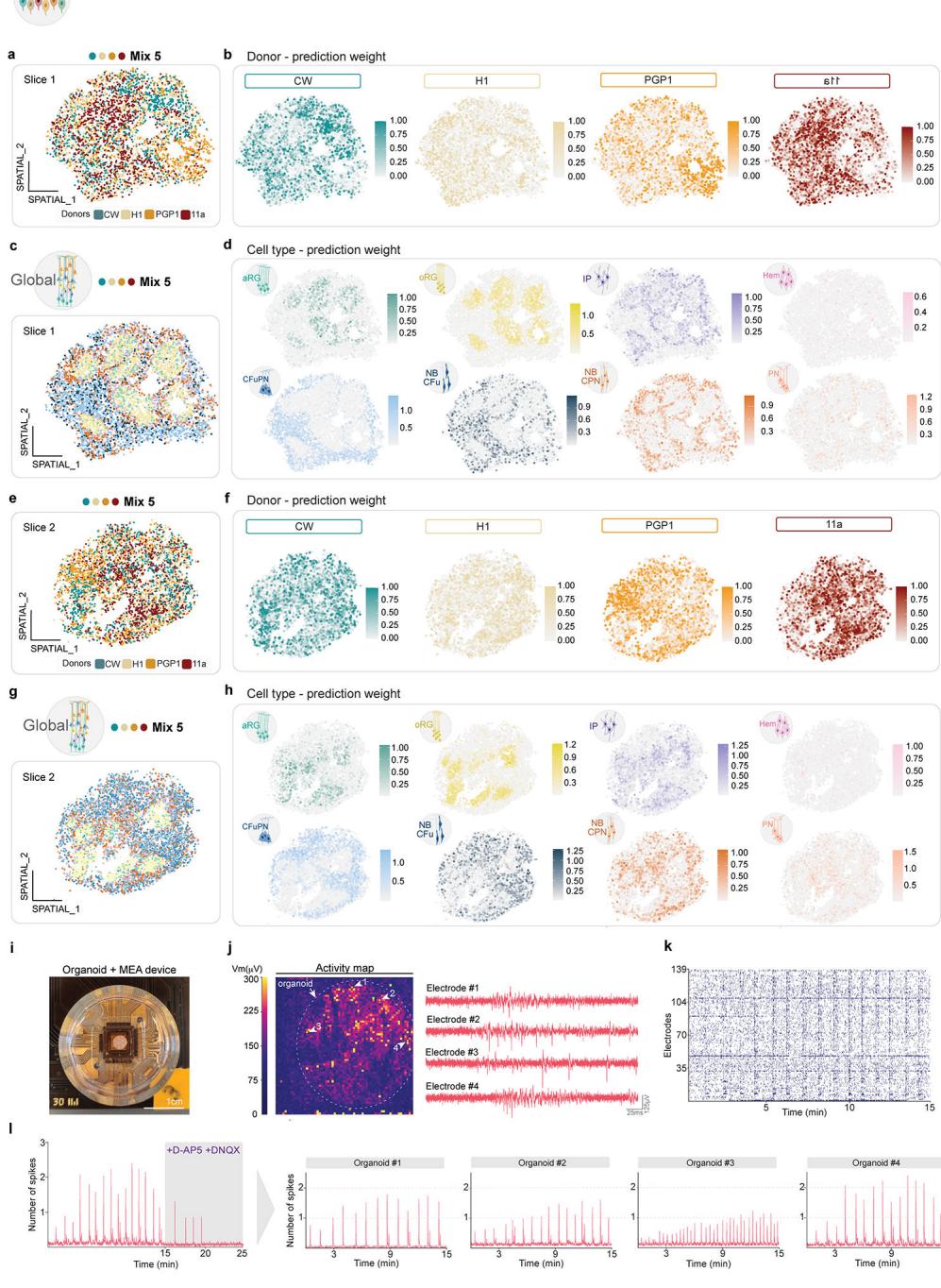
由于来自多个供体的人类PSC可在二维培养中共同生长和分化6–11,15–17,我们首先尝试在PSC阶段以同等比例混合4-5个细胞系来生成多供体人脑类器官(PSC-Chimeroids;图1a、b和扩展数据)。数据图1a–f、补充表1)。我们使用了H1、Mito210、PGP1、CW50037(下称“CW”)、GM08330(下称“GM”)以及11a多能干细胞系的不同组合(有关细胞系详情参见方法部分)。
解离的多能干细胞在96孔板中混合聚集形成胚状体,参照我们先前发表的方案18,将胚状体进行15-18天的模式诱导以促使其向背侧前脑分化,随后将初生类器官置于CDMII培养基中进行动态(振荡)培养以实现成熟(方法部分)。我们采用Census-seq10技术(方法部分)量化了各供体细胞系对单个类器官的贡献度。
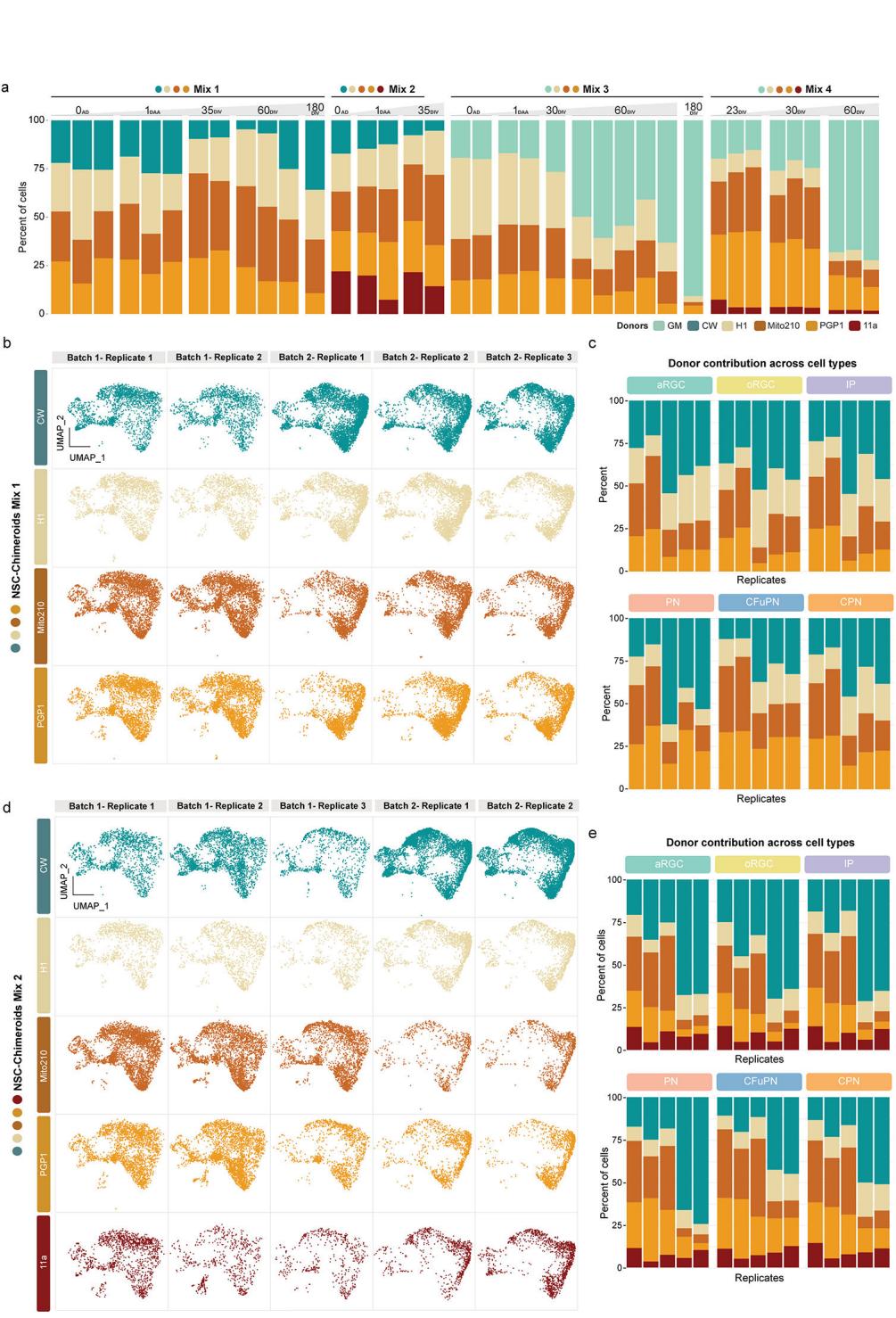
体外培养1个月时,PSC-Chimeroids即呈现个体供体的不平衡贡献现象,至3个月时该趋势加剧(图1b和扩展数据图1b)。我们通过独立实验在不同时间点测试了四种供体组合(Mix 1、Mix 3、Mix 4和Mix 5;补充表1),所有组合均观察到非均衡生长。含GM供体系的PSC-Chimeroids(Mix 3和Mix 4)出现该谱系的显著过度生长,培养至2个月时几乎完全占据类嵌合体(扩展数据图1b)。体外培养23天时,Mix4组PSC-Chimeroids中54%的细胞来源于GM供体(扩展数据图1b);培养至3个月时,基于遗传变异19的单细胞RNA测序监督性供体分配分析(方法学)显示GM谱系在Mix4组中贡献了近全部细胞(>99%)(图1b)。在不含GM的混合组中,Mito210细胞系呈现比例失衡的过高代表(Mix1组3个月时占细胞总量的84%,图1b)。在同时不含GM与Mito210的Mix5组中,CW谱系几乎被完全排除(3个月时仅存<3%细胞,图1b与扩展数据图1d–f)。由此可见,在拟胚体形成初期混合多能干细胞系会导致个体供体细胞比例严重失衡,这与既往多巴胺能神经元研究中的观察结果一致。神经元模型8。有趣的是,当多个供体维持表征时(混合5),所有保留的供体都能以基本平衡的方式为所有可识别细胞类型做出贡献,这表明Chimeroid方法本身并不会改变个体供体的细胞命运潜能(扩展数据图1d–i)。
多能干细胞具有高度增殖能力和命运可塑性,在类器官发育早期这些特性的微小差异可能导致后期细胞占比的显著失衡。若在多能干细胞完成神经命运定型后混合供体细胞系——此时细胞生长速度减缓且命运潜能更为受限——或可减少终末阶段供体贡献度的变异性。因此我们在神经模式形成完成后、于神经干细胞阶段进行供体混合(神经干细胞嵌合类器官)(图1c)。
为构建NSC-Chimeroids,我们首先按照先前发表的类器官培养方案18生成单供体EBs,并对其进行模式化诱导直至DIV15-18。将4-5个独立细胞系的新生单供体类器官解离后等比例混合(聚集日[AD]0),以每孔2万细胞的密度接种于96孔板(该细胞密度选择依据详见方法部分及扩展数据图2),转移至动态培养系统前允许其重新聚集2天(图1c及方法部分)。
在聚集后20天(DIV35),NSC嵌合体已发育出“玫瑰花结”——由表达端脑标记FOXG1的细胞、中间祖细胞(IP;TBR2+)和外放射状胶质细胞(oRG;HOPX+)组成的预期脑室区样结构,这些结构被新生的皮质传出投射神经元(TBR1+、CTIP2+)包围;玫瑰花结中心衬有ZO-1(一种存在于放射状胶质细胞足端的紧密连接蛋白)以及β-连环蛋白和巢蛋白信号,表明神经上皮具有正确极性(图1e及扩展数据图3、补充表2)。
我们使用Slide-seq技术检测了DIV55时期单个供体的空间组织结构,结果显示其与免疫组化观察到的组织形态相似(图1f,扩展数据图5a–h;方法)。值得注意的是,源自不同供体的细胞在神经玫瑰花结中基本相互混杂,表明供体间的自我分离并未驱动类器官结构的形成。
在不同时间点通过Census-seq定量(n=37次重复)(扩展数据图4a)以及通过3个月时scRNA-seq定量(n=10个独立Chimeroids类器官,103,602个细胞;图1d和扩展数据图4b-e)显示,在4种不同混合组合中,NSC-Chimeroids相比PSC-Chimeroids始终保持更均衡的供体贡献。值得注意的是,在PSC-Chimeroids中被单一供体主导(85%至99%)的混合组1、3、4(图1b),在NSC-Chimeroids中仍保留了所有供体的贡献(图1d)。3个月时,NSC-Chimeroids显示出背侧前脑标记物的正确表达(图1e,扩展数据图3c)。scRNA-seq数据显示,3个月时两个不同混合组的NSC-Chimeroids产生了我们皮质类器官模型18预期包含的全部细胞类型(图1g-j)。重要的是,每个供体都对嵌合体类器官内的各细胞类型有所贡献(图1g-j,扩展数据图4b-e)。
为评估功能成熟度,我们在4个月时对Mix 2 NSC-Chimeroids进行了多电极阵列电生理记录——该阶段此类类器官通常已具备电活性(方法部分)。我们检测到网络爆发活动可被NMDA与AMPA受体拮抗剂阻断,表明这种关联性活动由突触谷氨酸传递驱动,这与我们此前单供体皮质类器官在同阶段的观测结果一致(扩展数据图5i-l)。
总之,NSC-Chimeroids与我们已发表方案18,20中的标准皮质类器官发育过程相似,同时保留了在所有生成细胞类型中呈现多位供体的能力。
¶ 嵌合体类器官可控制增殖中的供体偏差
为探究嵌合体在缓冲供体生长速率差异方面的潜力,我们引入了一株具有显著增殖优势的多能干细胞系GM(图1b)(混合3与混合4,附表1)。尽管GM的加入确实改变了NSC-嵌合体中各供体的细胞占比(GM贡献了76-95%的细胞;图2a–c),但在培养3个月时所有供体细胞均持续存在,并能生成该阶段预期的全部细胞类型(图2b–d)——这与多能干细胞嵌合体形成鲜明对比,后者中大多数其他细胞系在3个月时几乎或完全消失。值得注意的是,GM供体细胞系产生的神经前体细胞比例(均值=31.0%,标准差=3.28%)高于其他供体(均值=13.8%,标准差=6.4%),尤其是外放射状胶质细胞(GM:均值=16.1%,标准差=0.6%;其他供体:均值=6.8%,标准差=2.6%;图2e),这可能驱动该品系的生长优势。假时序分析同样表明,与其他供体相比,GM在预测发育早期阶段的细胞比例更高(图2e)。
这一观察表明,在分化与命运定向的更晚期、增殖能力更弱的阶段混合祖细胞,或许能进一步改善供体细胞的生长偏差。因此我们通过解离并混合培养第23-25天(DIV23-25)的神经祖细胞,构建了神经祖细胞嵌合体(NPC-Chimeroids)(方法部分和图2f)。
对1月龄Mix 3 NPC-Chimeroids的免疫组织化学分析证实了神经玫瑰花结的形成及预期的细胞类型标志物(扩展数据图6a)。有趣的是,在早期时间点(1月和2月),NPC-Chimeroids总体尺寸小于NSC-Chimeroids,而PSC-Chimeroids则显得更大。这可能与解离-重聚集步骤后的培养时长有关:在1月时间点,PSC-Chimeroids自聚集后已培养35天,NSC-Chimeroids自解离-重聚集后培养17-20天,而NPC-Chimeroids仅培养10-12天。尽管如此,在1月和2月时间点,不同方案培养的类器官在极性、形态学及预期标志蛋白表达方面仍保持一致(扩展数据图1、3和6)。到第3个月时,尺寸差异逐渐消失,所有Chimeroids方案在形态和尺寸上基本无法区分(图2g和扩展数据图6c、d)。
对DIV90时期的NPC-Chimeroids进行单细胞RNA测序分析(n=2;4,132个细胞)显示,其达到了预期的细胞类型组成(图2h-i),且重要的是即使存在GM细胞系的情况下仍具有更均衡的供体贡献(GM贡献度:NPC-Chimeroids占细胞总数的17-31%;NSC-Chimeroids占76-95%;PSC-Chimeroids达>99%;图2j)。值得注意的是,GM细胞系仍显示出较高比例的增殖细胞类型(aRG、oRG与IP细胞总和:GM组为34.4%-35.5%,其他供体为11.0%-23.8%;二项混合效应模型p<10−15;图2j),这表明Chimeroid实验方案保留了供体间的内在差异。
总体而言,Chimeroid技术允许使用处于不同发育阶段的神经祖细胞作为聚集的起始细胞类型;在类器官发育后期进行供体混合可以克服显著的供体特异性生长优势,无需事先了解品系特异性特性。
¶ 多供体神经干细胞和神经祖细胞嵌合体中的细胞多样化与单供体类器官相当
为解析不同方案中形成嵌合体的起始细胞类型特征,我们在解离-重聚集步骤完成一天后对各方案中的新生嵌合体进行了谱系分析。在聚集后第1天(DAA),我们对新重聚集的Mix 2 NSC嵌合体与Mix 6 NPC嵌合体进行单细胞RNA测序(样本量=为10个混合嵌合体;NSC嵌合体8,831个细胞;NPC嵌合体4,325个细胞)(扩展数据图7)。两类新生嵌合体均包含祖细胞(aRG细胞占比分别为23%和11%,IP细胞占比分别为2.5%和2.2%)及早期分化神经元(占比分别为7.0%和23%);正如基于实验方案的预期结果,这些细胞群体的相对比例在不同方案间存在差异。
作为输入的分化阶段。两种方案在此阶段均保留所有供体的表示(扩展数据图7g、h)。
为了检验解离-重聚是否可能改变新生嵌合体类器官中细胞的分子特征,我们采用了Velasco等人系统20中已建立的类器官发育参考图谱(涵盖体外培养第23天至6个月的时间轴,下文简称“参考图谱”)。与第23天参考图谱的类器官数据对比显示,重聚后立即存在的细胞类型符合这些早期时间点的预期群体(扩展数据图7),包括该模型在此阶段发现的早期皮层下命运细胞20(扩展数据图7h)。数据表明,解离-重聚过程并未显著影响用于构建嵌合体的新生类器官中的细胞身份。
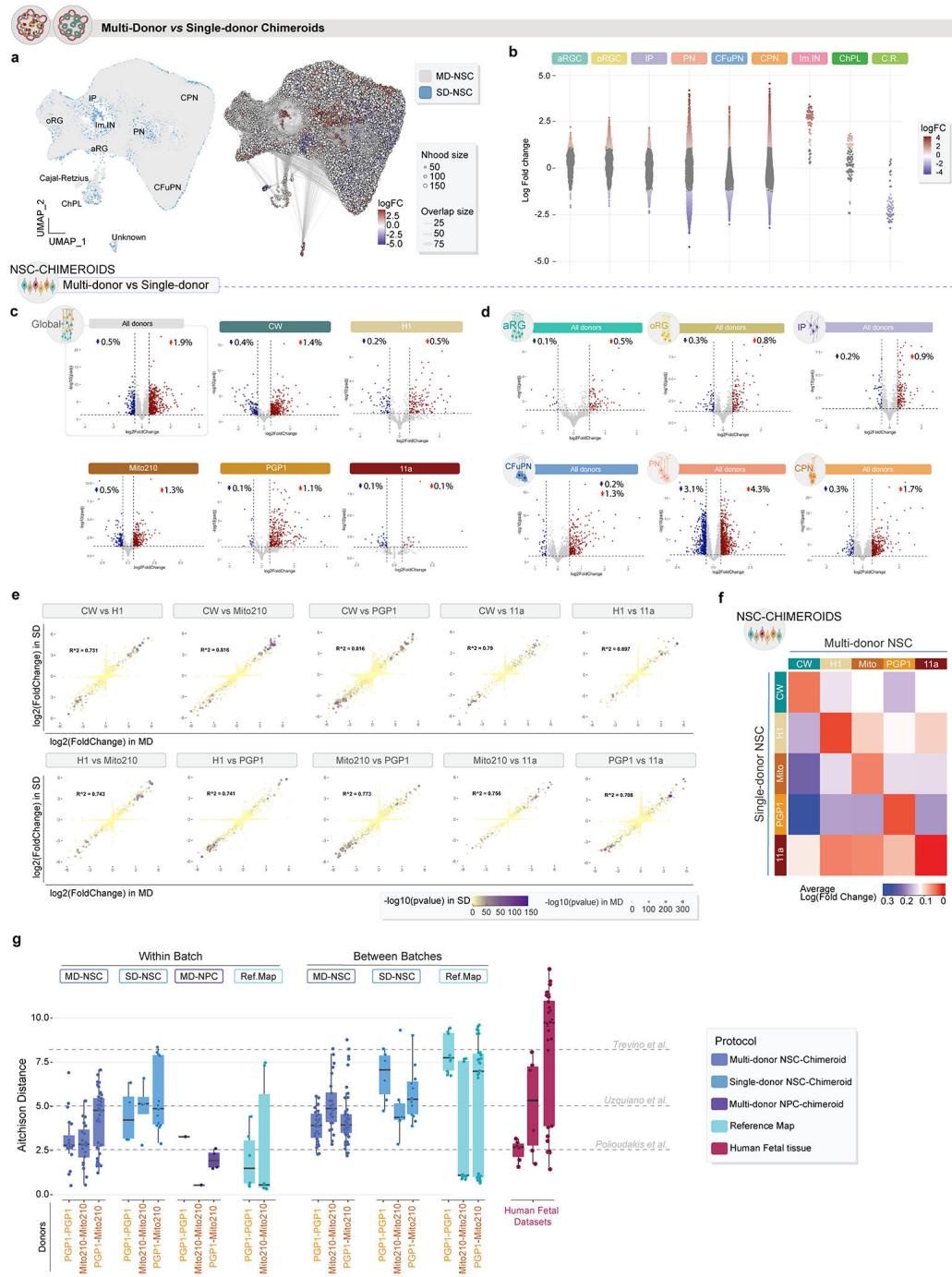
为了解嵌合体类器官方法是否影响各供体产生的细胞类型谱系,我们比较了同一供体细胞系在不同模型中产生的细胞组成。作为对照,我们通过解离并重聚集来自单一供体细胞系的新生类器官,生成了单供体(SD)NSC“模拟”嵌合体类器官,并通过免疫组化在1个月和3个月时验证了预期的分化标志物(扩展数据图8)。
我们通过单细胞RNA测序对来自单供体NSC-嵌合体的54,369个细胞(n=25个独立嵌合体)进行了3个月期的特征分析,并利用Milo21比较了多供体NSC-嵌合体(下称MD-NSC)与单供体NSC-嵌合体(下称SD-NSC)在细胞比例和整体表达谱上的差异——该工具可在不依赖细胞聚类身份的情况下检测单细胞数据中的差异性细胞丰度和表达方差。Milo分析表明,MD-NSC与SD-NSC嵌合体之间的表达景观仅发生微小全局偏移,离散细胞类型比例总体变化甚微(扩展数据图9a,b)。
我们接下来分析了在MD-NSC与SD-NSC条件下差异表达的基因(扩展数据图9c、d和附表3)。仅有少量基因(0.6-2.0%)在单个细胞类型中呈现显著差异表达(扩展数据图9c、d和附表4)。为验证单供体条件下发现的供体特异性基因表达模式是否能在多供体Chimeroids中检测到,我们比较了SD-NSC与MD-NSC条件下各细胞系之间的差异表达基因。不同供体间的差异表达基因在两种条件下高度相关:大多数在SD-NSC中显著差异表达的基因,在多供体Chimeroids中同样保持显著(扩展数据图9e、f)。
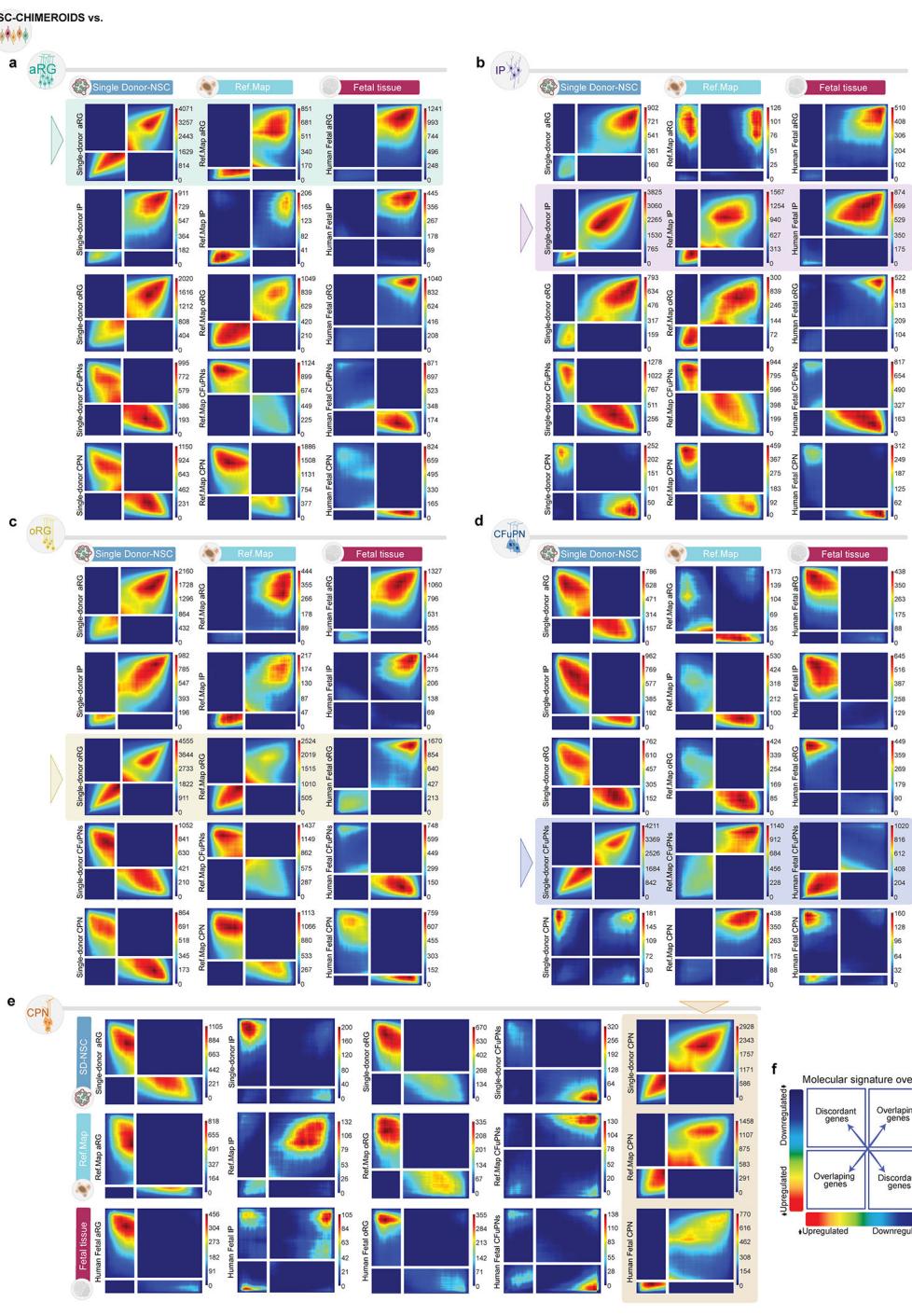
为测试Chimeroid模型中细胞类型的后续发育是否遵循原始类器官模型的相同模式,我们验证了所有3月龄Chimeroid模型均包含与同月龄参考图谱20类器官相同的细胞亚群(图3a-c)。此外,所有Chimeroid模型与参考图谱类器官中成熟的细胞类型标记基因均表现出高度一致性(对应细胞类型间标准化标记基因表达的皮尔逊相关系数范围为0.94-0.99;图3c和附表5)。值得注意的是,这些标记基因在Chimeroid细胞与相应内源性细胞类型之间也呈现我们先前发表的人类胎儿皮层单细胞RNA测序数据集20(方法部分)(皮尔逊相关系数,范围0.82-0.93,图3c);值得注意的是,MD-NSC嵌合体和SD-NSC嵌合体与胎儿细胞类型均呈现同等高度相关性。基于所有表达基因进行的全局转录相似性评估(秩秩超几何重叠检验,RR-HO24)同样证实了MD-NSC嵌合体、SD-NSC嵌合体、参考图谱类器官细胞20与内源性胎儿细胞20之间具有高度相似性(方法部分、图3d及扩展数据图10)。
各供体的细胞类型丰度在不同方案间基本一致(负二项模型,图3e)。为更精确评估细胞类型组成的相对差异,我们计算了方案内及跨方案的艾奇逊距离(方法部分和图3f),并将其与三个人类胎儿皮质数据集20,22,23的艾奇逊距离进行比较(图3f)。所有类器官和嵌合体类器官数据集均处于人类胎儿数据集范围内,表明嵌合体方案具有高度的可重复性,与个体内源性大脑相当。重要的是,参考图谱类器官、MD-NSC嵌合体与SD-NSC嵌合体的方案内距离不存在差异(威尔科克森秩和检验,p值范围0.42-0.75),这说明不同方案间细胞类型组成的类器官间变异程度具有可比性。
为了比较批次间变异与供体间变异,我们特别检查了在所有Chimeroid方案和参考图谱数据集(方法)中共享的两个细胞系,即PGP1和Mito210。对于每个供体和供体之间,批次内距离和批次间距离在所有比较中都具有非常相似的范围(扩展数据图 9g)。因此,无论是Chimeroid方法还是在同一系统中组合多个供体,都不会增加变异性。
为确认与内源性人类胎儿皮质细胞类型的转录相似性,我们采用参考标签传递技术25,将NSC-Chimeroids的细胞类型与两个参考数据集进行比对:内源性人类胎儿皮质20数据及我们构建的类器官参考图谱20,并进行了反向验证(方法部分)。在两个数据集中,Chimeroid细胞均主要被归入预期的参考细胞类型,这再次表明其表达谱与内源性皮质细胞类型及标准Velasco等人培育的类器官具有高度相似性(图3g)。
接下来,我们检验了不同方案间时间轨迹可能存在的差异。通过monocle3(方法)对单个细胞类型计算的拟时序轨迹显示,参考图谱类器官与所有Chimeroid模型之间具有相似的预测发育轨迹,主要细胞类型均以正确的时间顺序出现(图3h)。我们还检测了“RNA速率”(每个细胞中基因表达的变化速率)27;通过该方法发现MD-NSC和SD-NSC Chimeroids展现出相似的发育轨迹,且同一方案内的个体供体间高度相似(图3i和扩展数据图11a)。两种Chimeroid方案均未通过糖酵解基因集表达评估引发显著的细胞应激差异(扩展数据图11b-d)。这些数据共同表明,多供体和单供体NSC-Chimeroids均通过相似的分子轨迹发育。
总体而言,这些数据表明Chimeroid模型在相同供体混合物的多次重复实验中具有可重复性,且与我们已发表方案1,18,20制备的单供体类器官结果一致。多供体与单供体神经干细胞嵌合体在细胞复杂性方面,以及与人类内源性胎儿组织的分子相似性程度上,均与参照皮质类器官模型18,20保持相同水准。
¶ 乙醇和丙戊酸在嵌合体中诱导细胞类型特异性效应
为应用嵌合体模型研究个体对扰动反应的差异性,我们测试了两种可导致神经发育异常的神经毒性触发因素:乙醇(EtOH)和丙戊酸(VPA)。人类胎儿期接触乙醇可能导致胎儿酒精谱系障碍(FASD)12,28–36,其临床表型存在显著的个体间差异32。用于治疗癫痫和精神疾病的丙戊酸(VPA)在孕期使用时会增加后代罹患自闭症谱系障碍(ASD)的风险13,14。
我们使用两种不同的混合配方(混合1和混合2,见补充表1)培育出MD-NSC嵌合体,并在第45天至第70天期间(共30天)使用生理相关浓度的乙醇或丙戊酸进行处理(方法部分;图4a)。这一时间段靶向广泛的细胞类型,包括所有潜在的祖细胞类型以及源自皮层20的所有神经元细胞类型。处理后,嵌合体持续培养至体外培养第90天。
我们对来自两个供体混合物的处理过的3月龄MD-NSC嵌合体进行了单细胞RNA测序分析(混合物1含143,591个细胞,n=15个嵌合体;混合物2含131,636个细胞,n=13个嵌合体;图4b及扩展数据图12)。将两个处理组的细胞与未经处理的混合物1和混合物2MD-NSC嵌合体(前述)合并进行聚类和注释分析(方法部分)。
与未经处理的(对照组)Chimeroids相比(图4b),各处理组在细胞类型组成上均表现出显著差异(图4c)。VPA处理引起了未成熟GABA能中间神经元比例的急剧上升(平均丰度增加22倍,FDR=5.3*10−9,负二项混合效应模型)以及脉络丛细胞的增长(平均丰度增加6倍,FDR=1.3*10−7)——即使在控制了批次、混合度和来源供体等因素后(方法部分)仍保持显著(图4c,扩展数据图13a-c),这与既往关于VPA处理类器官模型的报道一致37。值得注意的是,我们此前研究发现中间神经元发育加速是不同自闭症谱系障碍风险基因1单倍剂量不足功能缺失突变导致的趋同表型之一,提示该细胞群体可能对神经发育风险因素具有特殊易感性。此外,乙醇处理使CPN与IP比例均有所上升(CPN的FDR=0.01,IP的FDR 0.01,NBME模型),而VPA处理的Chimeroids中这两类细胞比例均下降(CPN的FDR=0.01,IP的FDR 0.0035,NBME模型)(图4c)。
由于各细胞类型比例的变化具有相互依赖性(所有变化总和必须为零),我们采用了Milo21分析,结果证实VPA处理的MD-NSC嵌合体中未成熟IN细胞和ChPl细胞呈比例性增加而IPs细胞减少,同时乙醇处理的嵌合体中CFuPNs出现比例性下降(图4e-g)。此外,Milo在VPA处理的Chimeroid类器官中,oRG、CFuPN和CPN细胞群体凸显了表达谱的全局性改变,但离散细胞类型比例未发生整体变化;在EtOH处理的Chimeroid中,CPN细胞也呈现类似特征。VPA处理组17,824个细胞邻域中有6,327个(35.5%)发生显著改变,而EtOH处理组13,610个邻域中有5,589个(41.1%)发生变化(图4e-g)。值得注意的是,我们在SD-NSC Chimeroid模型中也观察到VPA处理对细胞类型比例的类似影响(图4d,扩展数据图13d,e)。
总体而言,这些研究结果表明,VPA和乙醇会引起处理特异性的细胞组成改变及细胞内在表达状态变化。这些改变可在多供体嵌合体中被检测到,且与单供体嵌合体中检测到的表型改变相似,从而证实了使用多供体嵌合体研究处理特异性反应的可行性。
¶ 嵌合体允许分析个体间对神经毒素反应的变异
接下来我们探究是否能在嵌合体类器官中检测到供体特异性对乙醇和丙戊酸处理的反应。虽然每位供体细胞都参与了所有细胞类型的组成(与干预条件无关)(图5a),但源自CW供体系的中脑多巴胺能神经干细胞在乙醇处理后比例下降(错误发现率=0.059,负二项混合效应模型),而在丙戊酸处理后比例上升(错误发现率=0.011),这表明这两种化合物存在处理方式与供体特异性的双重效应(图5b)。
随后,我们检测了VPA处理的MD-NSC嵌合体是否在表达反应上存在供体特异性差异。为量化每位供体的差异反应程度,我们在主成分分析(PCA)后分别计算了全局(跨所有细胞类型)及各主要细胞类型中每位供体伪批量样本间的欧几里得距离(方法部分)。
值得注意的是,不同供体对VPA的基因表达反应程度存在差异,这一现象在整体层面和单个细胞类型中均有体现(图5c);在大多数细胞类型中,11a供体属于受影响最严重的群体,而CW供体则属于受影响最轻微的群体。重要的是,每个供体对VPA的反应在单供体和多供体NSC-Chimeroid方案间具有基本一致性(图5d及补充表格6-7);我们未发现任何基因在两种方案中被VPA以相反方向显著失调的情况(方法部分)。
最后,我们在MD-NSC嵌合体中发现每个供体特有的VPA扰动基因(图5d);有趣的是,受影响程度越强的供体具有更高比例的供体特异性VPA扰动基因。重要的是,在VPA暴露后,相应的SD-NSC嵌合体中也富集了这组相同的独特基因(图5e、扩展数据图13f、g及补充表8)。
总之,我们的数据表明,多供体嵌合体系统能够在检测个体反应差异的同时,实现对多个供体实验干扰的全面检测。这些数据凸显了嵌合体系统在人类遗传变异对大脑干扰反应影响的高通量研究中的重要价值。
¶ 讨论
模拟个体差异对人类大脑疾病易感性的贡献一直存在困难。并非所有人类PSC细胞系在所有体外模型中表现都同样出色{11},这可能与重编程差异、表观遗传印记或对培养条件敏感度有关。
嵌合体类器官系统使得在单个类器官中研究多个人类个体大脑多种细胞类型的集体发育和行为成为可能。该方法将有助于对不同供体特征进行分析,例如疾病遗传风险、易感因素的存在与否或临床表型。尽管具有这些价值和发展前景,但需要考虑到嵌合体技术属于劳动密集型方法,且需要具备皮质类器官系统的专业知识才能成功实施;根据我们的经验,成功的嵌合体生成依赖于在混合步骤前验证新生类器官是否形成正确的早期模式。
中枢神经系统疾病的治疗方法往往仅对部分患者有效。未来的工作旨在扩大供体库规模,并结合细胞培养系统的自动化程度提升,或能实现对数百甚至数千个体进行人群水平差异研究。利用嵌合体技术大规模检测药物反应的能力,可实现基于数据驱动的患者治疗反应分层;长期积累的大型数据集有望为生成模型提供支持,从而在临床研究前预测药物疗效。
¶ 方法
¶ 人类多能干细胞培养
所有人多能干细胞系均按照先前描述的方法1,18,20进行培养。简言之,采用MTESR1培养基(StemCell Technologies)、mTESR+培养基(StemCell Technologies)或StemFlex培养基(Gibco),均添加1%青霉素-链霉素溶液(Corning),在预先包被1%Geltrex(Gibco)的细胞培养皿(Falcon)中于37°C、5% CO2条件下培养干细胞。所有多能干细胞系传代次数均保持在50代以内,并经支原体检测呈阴性(使用Lonza公司的MycoAlert PLUS支原体检测试剂盒进行检测)。
¶ 多能干细胞系的表征
本文使用的PSC细胞系包括:H1(男性,人胚胎干细胞[hESC])、Mito210(男性,诱导多能干细胞[iPSC],无神经系统疾病家族史对照)、PGP1(男性,iPSC对照)、CW50037(女性,iPSC,无神经系统疾病家族史对照)、GM08330(男性,iPSC,具有相关精神疾病家族史但临床未发病)以及11a(男性,iPSC对照)。
Mito210 iPSC细胞系由B. Cohen(麦克莱恩医院)提供;PGP1 iPSC细胞系38由G. Church(哈佛大学)提供;GM08330 iPSC细胞系39由M. Talkowski(麻省总医院)提供,该细胞系最初源自获取的成纤维细胞。来自科里尔医学研究所40的细胞系。CW50037 iPS细胞系源自加利福尼亚再生医学研究所(CIRM)iPS细胞库。H1人胚胎干细胞系(又称WA01)41购自WiCell研究中心;11a iPS细胞系42则获取自哈佛干细胞研究所。
所有细胞系的认证方式如下:PGP1 iPSC系通过短串联重复序列分析(由TRIPath于2018年进行)完成认证20;Mito210 iPSC系通过基因分型分析(Fluidigm FPV5芯片)完成认证,该分析由布罗德研究所基因组学平台完成20;H1和GM08330系通过STR分析(由WiCell于2021年进行)完成认证;CW50037 iPSC系采用SNP基因分型技术(基于Illumina全球筛查阵列,由布罗德研究所基因组学平台处理)进行细胞系鉴定和染色体异常检测。GM08330亲本系存在先前报道的20号染色体长臂间质重复现象;其余所有细胞系均显示正常核型。所有涉及人类细胞的实验均获得哈佛大学机构审查委员会和胚胎干细胞研究监督委员会的批准。
¶ 皮层类器官分化
根据Velasco方案1,18,20成功构建了背侧模式化的PSC-Chimeroids。简言之,在第0天,将无饲养层培养且融合度达75-85%的人iPSCs或hESCs用Accutase酶解为单细胞悬液,取9,000个细胞/孔重聚集于超低细胞吸附性的96孔V底锥形板中,所用培养基与其常规维持培养的多能干细胞培养基相同。第1天更换80μl皮质分化培养基I,其成分包含:Glasgow-MEM、20% Knockout血清替代物、0.1 mM MEM非必需氨基酸、1 mM丙酮酸盐、0.1 mM 2-巯基乙醇及1%青霉素-链霉素双抗。在0-6天期间,向培养基添加终浓度20μM的ROCK抑制剂Y-27632。模式化小分子Wnt抑制剂IWR1与TGFβ 抑制剂SB431542在0-15-18天期间持续添加,工作浓度分别为3μM与5μM。
第15至18天期间,将模式化EB在轨道振荡培养(赛默飞耐二氧化碳轨道摇床)中,使用超低吸附培养皿(康宁),于CDM II培养基内进行悬浮培养。该培养基包含DMEM/F12基础培养基(Gibco)、2mM Glutamax(Gibco)、1% N2补充剂(Gibco)、1%化学限定脂质浓缩液(Gibco)、0.25 μg/mL两性霉素B(Gibco)以及1%青霉素-链霉素双抗溶液(康宁)。至第35天,将细胞聚集体转移至搅拌式生物反应器(康宁),并在CDM III培养基中维持培养(该培养基为CDM II补充10%胎牛血清(GE-Healthcare)、5 μg/mL肝素(Sigma)及1%基质胶(康宁))。从第70天起,类器官转入CDM IV培养基培养(即在CDM III基础上添加B27补充剂(Gibco)与2%基质胶)。需要特别说明的是,对于PSC-Chimeroids体系,其起始步骤需参照已发表的Velasco类器官 protocol1,18,20,通过解离iPSC或ES细胞来构建EB。
¶ 嵌合体样聚集步骤
我们在NSC-Chimeroid生成阶段的细胞聚集体实验中,分别测试了9,000、12,000和15,000个细胞的聚集效果。当聚集细胞数量低于15,000时,所形成的Chimeroids体积过小且尺寸不均,免疫组织化学分析显示其向皮质方向的分化程度较低(扩展数据图2)。因此我们将每孔接种细胞数提升至15,000-18,000(数据未显示)及20,000个细胞。实验观察到每孔15,000、18,000、20,000乃至100,000个细胞均能成功生成遵循既定类器官培养方案18正确发育轨迹的Chimeroids(扩展数据图2)。针对NPC-Chimeroids,我们将细胞数增加至50,000个,因为该发育阶段的部分细胞不再参与类器官后续发育,且~20%的类器官细胞处于有丝分裂后期20;这些后期有丝分裂细胞无法重新进入细胞周期,在聚集后不太可能参与Chimeroids的发育进程。
¶ 多供体皮质Chimeroid生成
我们采用了以下供体组合:混合1(4个细胞系:CW、H1、Mito210、PGP1)、混合2(5个细胞系:CW、H1、Mito210、PGP1、11a)、混合3(4个细胞系:GM、H1、Mito210、PGP1)、混合4(5个细胞系:GM、H1、Mito210、PGP1、11a)、混合5(4个细胞系:CW、H1、PGP1、11a)以及混合6(GM、CW、Mito210、H1、PGP1、11a)。具体各实验包含的组合信息详见附表1。
嵌合体的生成基于一种重聚集过程,该过程使用来自背侧模式端脑类器官(皮质类器官)的推定NSC或NPC,这些类器官在不同发育阶段被解离;NSC-嵌合体和NPC-嵌合体分别来源于DIV15-18和DIV23-25的皮质类器官。
由于NSC-Chimeroid方案在我们测试的大多数细胞系中表现良好,我们认为在无需纳入具有极端增殖或分化偏性的PSC细胞系时,该方案是首选方案。因此我们开发了NPC-Chimeroid方案,以便能够将具有显著不同增殖或分化特性的PSC细胞系进行组合。
在预期发育阶段,使用沃辛顿木瓜蛋白酶解离系统试剂盒将来自每个供体的15-30个皮质类器官池酶解为单细胞悬液。该方案基于文献18,并经过改良以生成嵌合体类器官。具体而言,通过明场显微镜检查皮质类器官以确认形态正常,然后收集至低吸附1.5毫升离心管中。酶解前移除多余培养基。向管内加入预热的木瓜蛋白酶溶液(37°C, 500 μl),用P1000移液器反复吹打10次,随后在37°C轨道摇床中以90 RPM转速振荡孵育25分钟。继续用P1000移液器吹打组织块,再于37°C额外孵育5分钟。将所得溶液转移至含1毫升厄尔平衡盐溶液和600 μl卵粘蛋白抑制剂的15毫升离心管中,300g离心5分钟。弃去上清液,将解离细胞重悬于含20 μM ROCK抑制剂Y27632的1毫升CDM1培养基中。为消除聚集体并获得单细胞悬液,解离后的细胞通过35微米细胞过滤管(康宁)进行过滤,随后使用Countess II自动血细胞计数仪(赛默飞世尔科技)进行计数。将不同供体来源的细胞悬液按等比例混合后,在超低细胞吸附性的96孔V形锥底板(sBio PrimeSurface板;住友贝克莱特)中按每孔18,000-20,000个细胞(确保每个供体至少贡献1000个细胞)进行重聚集培养。次日更换为每孔100微升CDM2培养基。混合培养两天后,将重聚集的EB球体传代至超低吸附培养皿(康ning)中,并在轨道振荡条件下(赛默飞二氧化碳耐受型轨道摇床)继续培养。后续培养基更换遵循已发表方案18:在体外分化第35天更换为CDM3培养基,第70天更换为CDM4培养基。
¶ 乙醇和VPA治疗
多供体和单供体嵌合体在45天至75天期间分别接受乙醇或VPA处理。选择这个时间窗口是因为其靶向的细胞类型谱系广泛,包括所有潜在祖细胞类型以及源自大脑皮层的所有神经元细胞类型,涵盖放射状胶质祖细胞(aRG)、中间祖细胞(IP)、外层放射状胶质细胞(oRG),以及各类谷氨酸能锥体神经元亚型,例如叉形锥体神经元(CFuPN)和皮层投射神经元(CPN20)。为模拟孕期酒精暴露的典型生理波动,每两天直接向培养基添加50 μM浓度的乙醇(E7023-6,Millipore-Sigma),并在给药后使用Parafilm M封口膜(Bemis)密封培养板24小时以防止蒸发29。VPA(P4543-25G,Millipore-Sigma)则以0.7 mM临床相关浓度加入培养基,每周换液两次。两种处理均在体外培养第75天终止,并在培养3个月时对类器官进行分析。
¶ 用于冰冻切片的样本固定与处理
嵌合体在4°C条件下于12孔板中用4%多聚甲醛固定过夜,用1X磷酸盐缓冲盐水清洗3次后,置于30%蔗糖溶液中于4°C进行冷冻保护过夜。随后将样本包埋于牛明胶内:将含有10%牛明胶与7.5%蔗糖的明胶溶液在37°C预热15分钟,移除样本中的30%蔗糖溶液并替换为预热明胶,再于37°C孵育15分钟。同时用温热明胶溶液在塑料模具中覆盖2mm厚层,室温静置聚合。将嵌合体转移至预处理模具后,加入1mL温热明胶溶液完全覆盖样本,室温聚合3分钟,再于4°C预冷15-20分钟。最后将模具置于含100%乙醇与干冰的冷浴中冷冻2-3分钟,长期保存于−80°C环境。
¶ 免疫组织化学
对于免疫组织化学分析,采用冷冻切片机(Leica)切割14至20μm厚切片。冷冻切片在室温下稳定5分钟后,使用含10%驴血清(Sigma)及+0.3% Triton X-100(Sigma)的PBS溶液进行封闭。一抗(附表2)经封闭溶液稀释后孵育过夜。PBS冲洗4次后,冷冻切片在室温下与PBS稀释的二抗(1:1000;附表2)共同孵育。在室温下放置1小时(见表2),用PBS清洗4次,并用DAPI(按1:10,000比例溶于含0.1% Tween-20的PBS溶液+)染色15分钟以显示细胞核。
¶ 显微镜学
免疫荧光图像使用蔡司Axio Imager.Z2或蔡司LSM900共聚焦显微镜采集。Axio Imager.Z2的图像采用20倍物镜(像素尺寸:0.325微米)通过Apotome光学切片功能获取。在导出图像前,使用Zen Blue软件进行拼接处理和Apotome反卷积。对于LSM900,采用20倍物镜(像素尺寸:0.62微米)以3μ微米为步长采集Z轴堆栈图像,随后通过ZenBlue软件进行图块拼接。在Fiji43软件中进行了Z轴投影、通道合并及添加比例尺等后续处理。所有图像均进行亮度和对比度调整,且调整应用于整幅图像。
¶ 电生理学分析
在Mix 2 NSC类器官培养至4个月时(该模型通常在此阶段具有电活动特性¹),我们采用多电极阵列电生理记录技术进行检测。使用3Brain公司的Accura 3D CMOS-HD-MEA系统(结合BioCAM DupleX系统与Accura 3D芯片)⁴⁴,从类器官大面积分布单元中记录电信号。该3D芯片包含4,096个高度为90微米的μ针状电极,以64×64网格排列于3.8×3.8mm正方形区域内,采样率为20kHz,分辨率为12位。类器官在分析前14-21天更换为BrainPhys培养基¹,急性记录在37°C恒温迷你培养箱中进行,箱内充满碳合气。采用BrainWave v5记录15分钟自发活动。为验证所测电活动是否涉及突触传递,在记录结束时使用D-AP5(150μM)和DNQX(30μM)阻断NMDA与AMPA受体活性。通过BrainWave软件对原始通道轨迹进行尖峰检测,采用精确定时尖峰检测算法,设定8倍标准差作为检测阈值。
¶ 脑类器官解离与单细胞RNA测序
类器官的解离步骤参照先前所述方法18进行,但1月龄类器官除外——其解离过程按照嵌合体生成章节所述,使用低吸附1.5毫升离心管(Eppendorf)完成。解离后的细胞重悬于100μl PBS溶液,经35μm细胞过滤管(Corning)过滤去除聚集体,随后使用Cellometer K2仪器(Nexcelom)或Countess II全自动血细胞计数仪(Thermo Fisher Scientific)进行计数。将单细胞悬液加至Chromium Next GEM Chip G芯片(10x Genomics, 1000120),通过Chromium Controller制备单细胞GEMs。scRNA-seq文库采用Chromium Single Cell 3' Library and Gel Bead Kit v3.1(10x Genomics, 1000268)构建。当嵌合体包含多种遗传背景的细胞时,可利用遗传变异识别来自不同细胞系的双细胞团。这使得我们能够容忍更高的双细胞率,并在每个通道加载~20,000-30,000个细胞。最终文库根据摩尔浓度进行混合,使用NextSeq 500或NovaSeq 6000测序仪(Illumina)进行测序:读长1为28个碱基,读长2为55个碱基,索引读长1为8个碱基。若需必要,在首轮测序后我们会根据每个文库的实际细胞数量,并重新测序,目标是使每个样本的每个细胞产生等量的读数(目标测序深度为20,000次读取/细胞)。
¶ 单细胞RNA测序数据处理
所有单细胞RNA测序数据均使用10x Genomics Cell Ranger v7.1.045进行处理。通过mkfastq命令将原始BCL文件转换为FASTQ文件(采用默认参数)。随后对所得FASTQ文件运行Cell Ranger的count功能,基于10x Genomics下载页面提供的GRCh38人类参考基因组(https://support.10xgenomics.com/single- cell-gene-expression/software/downloads/latest GENCODE v32/Ensembl 98),为每个类器官生成基因-细胞计数矩阵。各样本的expect-cells参数均手动设置,数值范围在10,000至30,000之间,其余参数保持默认。最后使用R 4.2.2版本将Cell Ranger输出的filtered_feature_bc_matrix导入Seurat v4.3.025进行后续分析。
¶ 遗传解复用
基于scRNA-seq数据的遗传解复用分析中,我们采用demuxlet工具19对Cellranger生成的比对结果进行默认参数处理。通过对每位供体细胞系进行全基因组测序生成的参考变异呼叫格式文件,使用bcftools46进行归一化处理转换为双等位基因变异,并剔除未通过质控的单态变异。在后续分析前,我们从Seurat对象中移除了经demuxlet鉴定为遗传来源不明确或可能为异质性双联体的液滴。
为确定不同时间点和不同混合样本中PSC、NSC及NPC嵌合体各供体的比例丰度,我们采用Census-seq方法对低覆盖度全基因组测序数据11进行分析。该分析遵循https://github.com/broadinstitute/Drop-seq公布的Census-seq计算流程,使用Drop-seq软件包中的Census-seq功能并保持默认参数,同时采用与前述相同的各供体参考VCF文件。
¶ 细胞谱质量过滤、归一化、聚类、注释与整合
对于每个类器官细胞,表达基因少于200个、UMI少于500个、UMI超过20,000个或线粒体RNA含量高于15%的细胞谱系均被剔除。设置这些阈值旨在保留所有细胞类型,以及可能受乙醇或丙戊酸暴露不利影响的细胞;然而在最终数据集中,仅0.15%的分析细胞表达基因数低于500个,且线粒体RNA含量超过10%的分析细胞占比不足0.43%。使用Seurat的SCTransform函数处理每个类器官的过滤计数矩阵,并剔除线粒体RNA百分比的影响。对SCTransform识别的可变特征进行主成分分析,随后采用Seurat的FindNeighbors函数构建k-最近邻图(k=20),选取前30个主成分,再通过FindClusters函数进行Louvain聚类,分辨率参数设定在0.2至1.0之间。
来自多个Chimeroids的单细胞表达数据被合并成几个更大的联合数据集,并根据协议和处理方式进一步处理,如下:PSC-混合5的嵌合体(n=2;15,612个细胞)使用Seurat的merge函数进行合并,随后通过SCTransform进行联合重归一化处理;混合3和混合4的NSC与NPC嵌合体(n=6;52,771个细胞)则参照Seurat整合流程进行集成,具体包括使用SelectIntegrationFeatures(nfeatures参数设为3000)、PrepSCTIntegration、FindIntegrationAnchors及IntegrateData函数;混合1和混合2的对照组、EtOH处理组与VPA处理组的多供体NSC嵌合体,以及单供体NSC嵌合体(n=93;420,288个细胞)通过两步法整合:多供体NSC嵌合体基于原始计数矩阵使用Seurat的merge函数合并,采用NormalizeData、FindVariableFeatures(nfeatures设为3000)和ScaleData函数进行联合重归一化与标准化,对联合表达矩阵进行PCA分析后,采用与单数据集相同的方法构建k近邻图并进行聚类。将UMI计数异常偏低的聚类判定为低质量细胞予以剔除(20,581个细胞)。单供体NSC嵌合体经类似流程完成合并、处理及过滤(剔除4,133个细胞)。最后将整合后的多供体与单供体NSC嵌合体原始计数矩阵通过Seurat的merge函数合并,并采用相同方法进行重归一化、标准化与再次聚类。
对每个合并的单细胞RNA测序数据集进行主成分分析,采用均匀流形逼近与投影对细胞特征(前30个主成分)进行可视化嵌入,并执行最终轮次的k近邻图构建与聚类分析。在各数据集内部,我们通过以下组合方式对每个聚类进行人工细胞类型标注:(1)经典标记基因表达谱,(2)基于Seurat的FindMarkers功能确定的各聚类上调基因列表,(3)通过Seurat的FindTransferAnchors和MapQuery功能,从我们既往发布的Velasco方案类器官发育参考图谱20中自动迁移表达谱标签。基于联合聚类标签,在每个合并或整合数据集中进一步优化细胞类型分类(补充表9-12)。通过UMAP对细胞特征(前30个主成分)进行降维可视化。将UMI计数异常低的聚类标记为低质量细胞并排除下游分析。对于初步仅能鉴定为循环祖细胞的聚类,通过以下方式进行亚群分析:提取该聚类细胞子集,重新执行主成分分析、k近邻图构建及聚类流程,并利用HOPX、EOMES和SOX2的表达特征将亚群明确鉴定为顶端放射状胶质细胞、外侧放射状胶质细胞或中间祖细胞。
¶ 对已发表人类胎儿数据的分析
为进行比较,采用了三个先前已发表的人类胎儿皮层数据集。
首先,Polioudakis等人提供的Drop-seq数据集23包含来自妊娠17周和18周人类胎儿皮层样本的33,986个细胞及相关元数据(含各细胞类型注释),该数据从CoDEx查看器(http://solo.bmap.ucla.edu/shiny/webapp/)下载。我们使用原作者标注的细胞类型标签计算样本间的Aitchison距离。其次,Trevino等人的scRNA-seq数据集22包含来自妊娠16周、20周、21周和24周人类胎儿皮层样本的57,868个单细胞转录组及相关元数据(含细胞类型从 https://github.com/GreenleafLab/brainchromatin/blob/main/links.txt 下载的任务分配数据中,我们采用原作者标注的细胞类型标签来计算各样本间的 Aitchison 距离。
第三,我们之前的snRNA-seq数据集(Uzquiano等人20),包含4位捐赠者的胎儿皮质样本(孕后14、15、16和18周),我们将其筛选为仅包含与3个月类器官或Chimeroid相关(或具有密切类似物)的细胞类型(aRG、oRG、IP、CFuPN、CPN、IV层、CGE-INs、胶质前体细胞和少突胶质前体细胞[OPCs])。这产生了52,658个细胞,用于测量该数据集内胎儿样本之间的艾奇逊距离,以及关联胎儿数据和Chimeroid中跨细胞类型的标记基因表达,并将Chimeroid细胞类型标签映射到胎儿细胞上(图3)。为通过参考标签转移将胎儿细胞类型标签映射到Chimeroid上,该数据集被进一步限定为每种细胞类型最多5,000个细胞类型,以及移除第四层细胞。
¶ 轨迹分析
使用velocyto Python软件包计算每个未经处理的Mix 1/Mix 2 MD NSC-Chimeroid的剪接与未剪接计数矩阵。将这些剪接/未剪接矩阵合并后,采用scVelo Python软件包计算每个细胞中基因的RNA速率,并将其投影到MD/SD Chimeroid混合Seurat对象的UMAP嵌入中。对每个未经处理的SD NSC-Chimeroid样本重复相同流程。最终通过scVelo的pl.velocity_embedding_grid函数实现速率可视化。
对每个数据集分别计算伪时间,包括3月MD NSC-Chimeroids、3月SD NSC-Chimeroids、3月NPC-Chimeroids以及3月参考图谱类器官(仅包含源自PGP1或Mito210细胞系的3月类器官子集),使用Monocle3(v 1.3.4)进行R语言分析并以aRGs作为根细胞。针对每个数据集,将伪时间值缩放至最小值为0、最大值为1。通过ggplot2的geomdensity_ridges函数可视化各数据集中不同细胞类型和供体在伪时间轴上的分布密度。
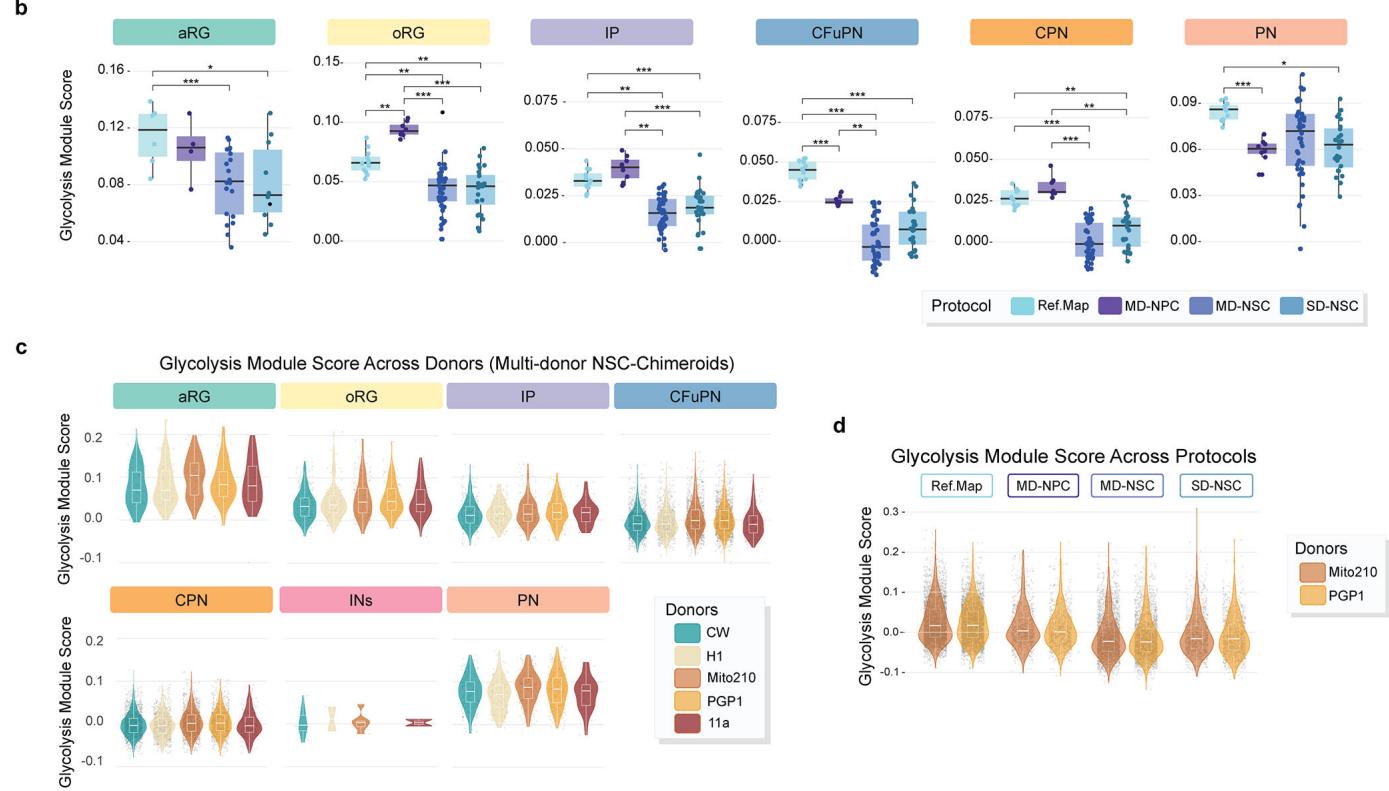
¶ 糖酵解标志分析
采用MSigDB Hallmark基因集中的糖酵解基因集(包含200个基因),通过Seurat的AddModuleScore函数对以下数据集中的20,000个细胞随机子集进行模块评分计算:3月MD NSC-Chimeroids、SD NSC-Chimeroids、NPC-Chimeroids以及参考图谱类器官样本(仅包含源自PGP1或Mito210细胞系的3月类器官)。为验证不同类器官与Chimeroids方案在各主要细胞类型(aRG、oRG、IP、PN、CFuPN、CPN和IN)中是否呈现差异化的糖酵解表达模式,分别对参考图谱类器官中各细胞类型的全部细胞、以及Chimeroids中每位供体的各细胞类型细胞计算糖酵解模块评分均值。针对每种细胞类型,使用以起源供体作为随机效应的混合线性模型,进行数据集间两两比较,并通过R语言基础anova函数比较包含与不包含“方案”作为协变量的模型。
¶ 可重复性以及与胎儿组织和皮质类器官的比较
Aitchison距离定义为每个样本中经中心对数比转换后的细胞类型丰度之间的欧几里得距离,通过R包robCompositions(v2.4.1)的aDist函数计算所有可能的样本对(样本指来自同一供体的类器官或嵌合体中的所有细胞)。该距离用于衡量成分数据的成对差异,其计算考虑了任何给定样本中细胞类型总丰度必须总和为100%的特性(因此某种细胞类型的扩增必然导致其他细胞类型丰度的减少)。采用Wilcoxon秩和检验比较各实验方案内重复样本间的Aitchison距离。
为了比较个体匹配供体系内不同方案间的变异性,我们专门针对PGP1和Mito210样本(这两个是唯一存在于所有四种相关方案中的供体系:MD-NSC、SD-NSC、MD-NPC嵌合体以及参考图谱类器官)进行了批次内和批次间距离的比较。这些成对艾奇逊距离还根据其代表的是两个PGP1样本、两个Mito210样本,还是一个PGP1与一个Mito210样本进行了进一步分组。
Seurat的FindTransferAnchors和MapQuery函数按照Seurat 4.3标签转移教程中描述的方式使用,以将标签从胎儿皮质样本和皮质类器官转移到Chimeroids和单供体Chimeroids上(反之亦然)。
Seurat的FindMarkers函数(未设置倍数变化或显著性阈值)被用于独立生成未经处理的NSC-Chimeroids、胎儿皮质组织或参照图谱皮质类器官中每种细胞类型的标记基因列表。该列表通过Wilcoxon秩和检验计算出的显著性进行排序:最显著上调的基因位于列表顶端,最显著下调的基因位于列表底端。采用RRHO2 R软件包(版本1.0)改进的秩秩超几何重叠检验,将各NSC-Chimeroid细胞类型的标记基因列表分别与胎儿及类器官标记列表进行比对。
针对19种典型细胞类型标记基因中的每一种,我们在5个数据集(混合1/混合2 NSC-Chimeroids、NPC-Chimeroids、单供体Chimeroids、参考图谱类器官和内源性胎儿皮层)中分别计算了5种主要细胞类型(aRG、oRG、IP、CFuPN和CPN)在所有细胞中的平均标准化表达量,以便在可比较的细胞类型之间进行跨数据集的标记基因表达对比。我们计算了内源性胎儿组织与每个类器官及Chimeroid数据集中对应细胞类型之间的表达量皮尔逊相关系数,同时计算了参考图谱类器官与各Chimeroid数据集之间的相关系数。
使用EdgeR版本3.40.247–49检测MD-NSC嵌合体与SD-NSC嵌合体、MD-NPC嵌合体及参考图谱类器官中共有的各供体细胞系在细胞类型丰度上的差异。针对每个供体细胞系和实验方案,以MD-NSC嵌合体为基线报告差异结果。
¶ 治疗条件间的细胞类型丰度、供体丰度和邻域变化
采用负二项混合效应模型检验对照组Chimeroid与VPA/EtOH处理组Chimeroid之间的细胞类型丰度差异。具体而言,使用lme4(1.1.33版本)的glmer.nb函数,以每个Chimeroid内供体的细胞类型计数矩阵为输入数据,将供体与Chimeroid的总细胞数对数作为偏移量,设定Chimeroid分化批次和供体混合类型(Mix 1或Mix 2)为固定效应,同时将供体身份(用于解释供体间细胞类型丰度总体差异及供体内重复样本相似性)和单个Chimeroid(用于解释共享类器官内供体间细胞类型丰度相似性)作为随机效应。最终构建的模型公式为:细胞类型~~处理++偏移量(log(文库大小))++批次++混合类型++(1||Chimeroid)++(1||供体)|。通过R统计包(4.2.2版本)的anova函数,将包含处理固定效应的模型与去除该效应但其余结构相同的模型进行比较,计算处理对细胞类型丰度影响的显著性。基于所得p值采用Benjamini-Hochberg(BH)方法计算错误发现率。
使用EdgeR版本3.40.247–49检测供体丰度对VPA或EtOH处理的响应变化。具体而言,将每个嵌合体内各供体的细胞计数矩阵依次通过以下函数处理:calcNormFactors(方法设为“TMM”)、estimateDisp(趋势设为“无”)、glmQLFit(丰度趋势设为“假”)以及glmQLFTest,过程中采用包含嵌合体分化批次和供体混合作为附加协变量的设计公式。显著性以经BH法计算的FDR值进行报告。
使用miloR R软件包1.6.021版评估重叠细胞邻域内的差异丰度,每个邻域规模为50-200个细胞。针对每种处理条件(VPA和EtOH),将表达矩阵限定为仅包含对照组和处理组嵌合体细胞中变异度最高的3,000个基因,对该子矩阵进行PCA分析,并将结果导入Milo对象进行后续分析。运行miloR的buildGraph函数时设置k=30和d=30参数,随后执行makeNhoods和calcNhoodDistance。通过testNhoods函数以~Mix +Donor +Treatment为实验设计,检验每个邻域内处理组与对照细胞的差异丰度(DA)。显著性以空间FDR值呈现,该值由miloR根据DA p值及邻域间关系计算得出。同样方法应用于未处理MD NSC嵌合体与未处理SD NSC嵌合体的比较,因SD嵌合体非供体混合样本,故剔除“Mix”协变量。
¶ 伪批量谱和差异表达分析
为了总结乙醇和丙戊酸处理的嵌合体中的基因表达变化,我们通过主成分分析降维后测定了样本间的距离。针对每组伪批量表达谱(全局、aRG、oRG、IP、CFuPN和PN),我们进行主成分分析以识别主要变异轴,随后基于所有主成分计算同一供体的对照组与丙戊酸处理嵌合体之间的欧几里得距离。伪批量表达谱的生成采用全局方式(即每个伪批量表达谱包含来自同一供体的所有细胞的UMI)。
在单个嵌合体内按供体进行分析,以及按细胞类型进行分析(其中一个伪批量谱包含来自单个嵌合体内同一供体同类型所有细胞的UMI),通过对每个基因的UMI计数进行汇总,并在适用时计算每百万对数计数作为表达值。包含少于20个细胞的伪批量谱将被排除在下游分析之外。
对全局及各类细胞表达谱的全局伪批量表达矩阵中的高变基因(定义为平均表达量加上方差与平均表达比值的对数大于1的基因)进行了主成分分析(PCA)。使用stats R包中的dist()函数计算了每个PCA内所有PC(每种情况下PC数量等于通过质量和异常值筛选的伪批量样本数)之间各伪批量谱的欧几里得距离。通过方差分析(ANOVA)评估对照组与处理组样本间的距离在五个供体系间是否存在显著差异。当ANOVA得出的p值小于0.05时,采用事后Tukey检验进行供体间的两两比较。
对每位供体,分别对未经处理与VPA处理的多供体NSC嵌合体、以及未经处理与VPA处理的单供体NSC嵌合体进行差异表达分析(DEA)。该方法通过将分化批次作为附加协变量,对伪批量表达矩阵应用DESeq2。在多供体分析中,仅在单个供体中出现显著差异表达(FDR校正p值<0.05且对数2倍变化绝对值>0.5)的基因被视作该供体的“独特”基因。这些供体特异性独特基因作为定制基因集,用于对应单供体DEA结果的基因集富集分析(GSEA)。针对每位供体,根据单供体NSC嵌合体中未经处理与VPA处理组间的倍数变化绝对值对基因进行排序,并采用Kolmogrov-Smirnov检验验证供体特异性独特基因是否比随机基因具有更高排序等级。同时进行反向验证:从单供体DEA中识别各供体独特基因,并将其作为基因集用于多供体DEA的GSEA分析。
为评估未经处理的Mix1/Mix2混合培养NSC嵌合体中不同供体间的转录差异,我们采用DESeq2对全体供体的聚合表达谱进行两两比较(包括CW-H1、CW-Mito210、CW-PGP1、CW-11a、H1-Mito210、H1-PGP1、H1-11a、Mito210-PGP1、Mito210-11a、PGP1-11a组合)。在未经处理的单供体培养NSC嵌合体中也对相同供体组合进行了等效差异表达分析。为探究供体间转录差异在两种培养方案中是否具有保守性,我们计算了两种方案中log2折叠变化的皮尔逊相关系数。此外,通过费希尔精确检验评估了两种方案中显著差异表达基因(校正p值<≤0.05且log2折叠变化绝对值>≥0.5)是否存在显著重叠。
同样地,为了评估SD与MD NSC-Chimeroids之间的转录差异,我们对各细胞系的伪批量分析谱应用了DESeq2分析,包括整体分析和各主要细胞类型(aRG、oRG、IP、CFuPN和CPN)的独立分析,并以“培养方案”(SD与MD对比)作为测试变量,并将批次作为额外协变量。此外,使用所有细胞系进行了类似测试,包括供体来源这一额外协变量。
在SD与MD NSC-Chimeroids中,我们未发现任何基因被VPA以相反方向显著失调;仅有极少比例基因(0.14%-1.23%)在某一实验方案中被VPA显著扰动,但在另一方案中呈现相反符号(未达显著性)的log2倍数变化。尽管此类基因数量过少(每位供体平均24个)无法支持详细分析,但这些基因在各细胞系中未经处理的单供体与多供体NSC-Chimeroids间的差异表达基因中呈现富集现象。
¶ 对嵌合体进行空间转录组分析以映射个体供体。
为绘制嵌合体中单个供体的空间组织分布,我们按照制造商协议(CB-000470-UG v2,Curio Biosciences)使用Curio Seeker 3x3试剂盒。将2月龄单个嵌合体在含2 U/ml RNase抑制剂(货号N8080119, Thermo Fisher Scientific)的PBS溶液(货号100-10-023, Gibco)中清洗两次,随后于组织冷冻培养基(货号72592-B, Electron Microscopy Sciences)中孵育1分钟,并包埋于BEEM平板包埋模具(货号70904-12, Electron Microscopy Sciences)。将模具转移至干冰环境冷冻20分钟后保存于−80°C环境。切片前将模具与CryoCube(Curio Seeker 3x3试剂盒组件)在冷冻切片机内−18°C平衡20分钟。使用冷冻切片机(CM1950, Leica Biosystems)以10μm厚度切片,毛笔展平后谨慎贴附于Curio Seeker 3x3mm芯片,通过指腹温融固定。取30μm厚CryoCube切片覆盖于组织切片上方,同法温融后−80°C冷冻保存至3天。将间距20μm的两个嵌合体切片分别贴附于独立芯片,后续步骤按试剂盒说明(CB-000470-UG v2, Curio Biosciences)进行。标签化步骤使用Nextera XT文库制备试剂盒(货号FC-131-1024, Illumina),按推荐方案加入1200 pM DNA。
文库合并后使用Nextseq 1000进行测序,读长设置如下:(Read 1,50 bp;Index 1,8 bp;Index 2,8 bp;Read 2,50 bp)。通过Curio Seeker分析流程v2.0.0(CurioBioscience平台在线工具:https://curiobioscience.com/bioinformatics-pipeline/)对测序文件进行处理以进行基因表达分析。
比对后的测序读数被分割为单个BAM文件,每个文件对应一个空间索引磁珠。利用上述参考VCF文件,对每个BAM文件进行Census-seq分析,以确定每个供体的空间分布。采用空间转录组细胞类型反卷积算法RCTD50(通过spacexr R软件包v2.2.1的"双胞模式"实现),以参考图谱数据集20中2月龄Velasco类器官的单细胞RNA测序数据作为参照,对表达矩阵进行分析,从而为空间坐标分配细胞类型权重。
¶ 扩展数据
¶ 扩展数据图1. PSC嵌合体呈现不均匀的供体组成但具有正常的细胞类型组成。
a、PSC-Chimeroid方案示意图。b、显示供体组成的堆叠条形图,通过低通量全基因组测序的Census-seq方法测定,来自不同混合比例和时间点的PSC-Chimeroids,标记为自接种日起的天数(DIV0)。对于DIV0和DIV1时间点,n=4个Chimeroids已被合并分析。c、左图:3个月大PSC-Chimeroids的明场图像;比例尺:1毫米。右图:3个月PSC嵌合体中SATB2、TBR1和MAP2的免疫标记。比例尺:500μ米。d,3个月时整合PSC嵌合体的UMAP,按注释细胞类型(左图)和通过demuxlet确定的供体系(右图)着色。e,按供体分列的两次不同重复的UMAP。f,PSC嵌合体中细胞类型比例的条形图(n=2),按供体进行解复用。g,1个月PSC嵌合体的免疫标记显示早期祖细胞(SOX2)、皮质祖细胞(EMX1);玫瑰状中心以ZO-1(一种存在于放射状胶质细胞终足的紧密连接蛋白)和NESTIN为边界,表明神经上皮极化正确。CFuPNs神经元由TBR1标记,神经元树突由MAP2标记。h,2个月PSC嵌合体的免疫标记显示早期祖细胞(SOX2)、中间祖细胞(TBR2)和外放射状胶质细胞(HOPX)。CTNNB1标记神经玫瑰状中心,表明神经上皮极化正确。i,3个月PSC嵌合体的免疫标记显示皮质标记物,如SATB2(上层皮质神经元)和CTIP2(深层皮质神经元)。白色箭头指向神经玫瑰状结构(下图放大显示)。比例尺:100μ米。
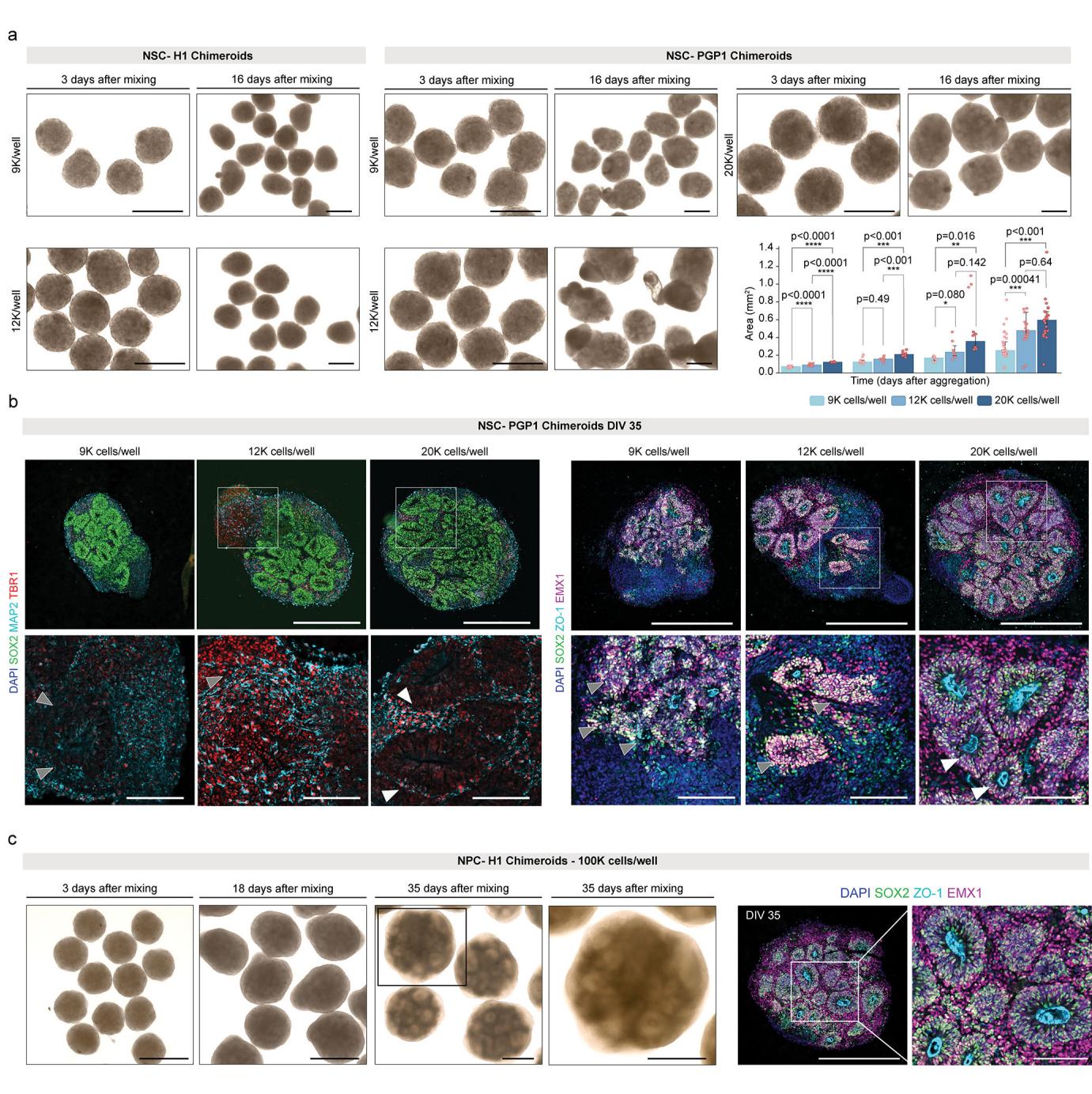
¶ 扩展数据图2. 通过聚集不同数量细胞构建的NSC-Chimeroids展现出差异性发育。
a. 单供体H1 NSC-Chimeroids在重聚集后第3天和第16天(左图)分别以9,000(上排)和12,000(下排)细胞/孔接种的明场图像;单供体PGP1 NSC-Chimeroids在重聚集后第3天和第16天(右图)分别以9,000(左上)、12,000(左下)和20,000(右上)细胞/孔接种的明场图像。比例尺:500μm。右下方的柱状图显示PGP1 NSC-Chimeroids在不同聚集细胞数条件下的随时间生长情况。柱体表示中位数,须线表示上下四分位数(所有4个时间点共n=170个Chimeroids)。显著性通过方差分析及双侧检验计算得出。Tukey事后成对检验。P值:*** < - 0.001;**** - <0.0001。b. PGP1单供体NSC嵌合体的免疫标记,通过聚集指定数量的细胞制成,在DIV35时。上图显示整个类器官;下图显示指定部分的放大。左图,SOX2(祖细胞)、MAP2(神经元树突)和TBR1(深层神经元)的免疫标记。右图,SOX2、ZO-1(紧密间隙连接)和EMX1(背侧皮质祖细胞)的免疫标记。比例尺:500 μ微米(上图)和125 μ微米(下图)。箭头指示非皮质(灰色)和皮质(白色)区域。c. 左图:H1单供体NPC嵌合体的整个类器官明场图像,在聚集时接种100,000个细胞,混合后18天和35天。比例尺:500 μ微米。右图:H1单供体NPC嵌合体的免疫标记,显示SOX2、ZO-1和EMX1。比例尺:500 μ微米和125 μ微米(放大)。
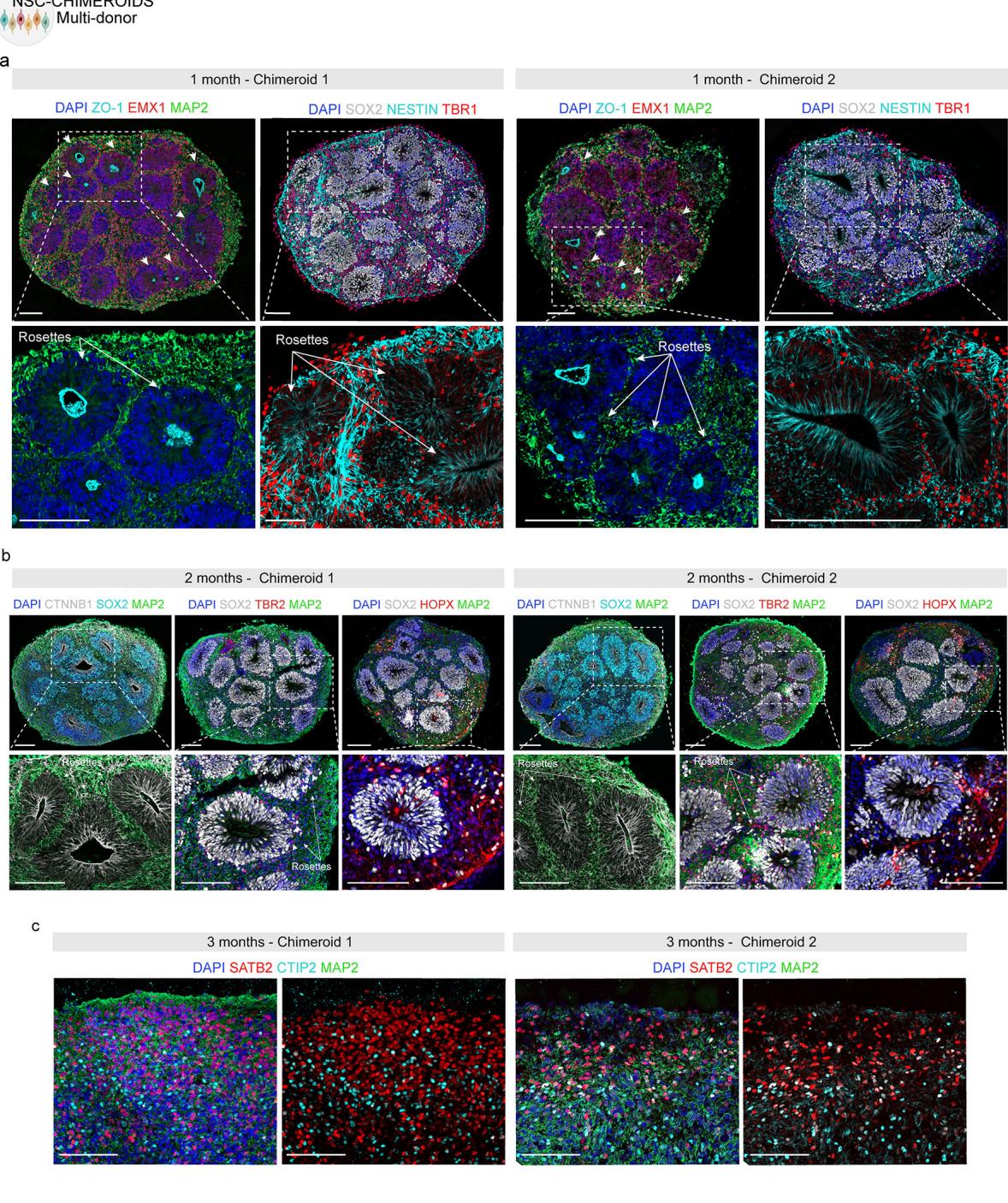
¶ 扩展数据图 3. 多供体NSC嵌合体显示适当的分化标记物{v*}。
a、1个月MD-NSC嵌合体的免疫标记显示早期祖细胞(SOX2)和皮层祖细胞(EMX1);玫瑰结中心由紧密连接蛋白ZO-1包绕,该蛋白存在于放射状胶质细胞的终足,同时NESTIN信号表明神经上皮极性正确。CFuPNs神经元由TBR1标记,神经元树突由MAP2标记。b、2个月MD-NSC嵌合体的免疫标记显示早期祖细胞(SOX2)、中间祖细胞(TBR2)和外放射状胶质细胞(HOPX)。CTNNB1标记神经玫瑰结的中心结构。显示正确极化的神经上皮。c、3月龄MD-NSC嵌合体的免疫标记显示皮质标志物,如SATB2(上层皮质神经元)和CTIP2(深层皮质神经元)。白色箭头指向神经玫瑰花结。比例尺:100 μ微米。
¶ 扩展数据图4. 在不同供体中NSC-Chimeroids形成适宜的细胞类型组成。
a、堆叠条形图显示了来自不同混合比例的多供体NSC-Chimeroid的供体组成情况,该数据通过低覆盖度全基因组测序中的Census-seq方法测得。并在不同时间点进行标记,即重聚后天数(DIV;针对DIV0和DIV1时间点,已汇总n=4个嵌合体)。b-e图分别为:按供体分列的3月龄NSC嵌合体UMAP图(b、d),以及混合1(4名供体)与混合2(5名供体)各细胞类型的供体贡献堆叠条形图(c、e)。
¶ 扩展数据图5. NSC-Chimeroids在不同供体间呈现均匀空间分布。
a,切片#1。来自2月龄MD-NSC嵌合体(混合5)的Slide-seq数据空间分布图,通过Census-seq方法以最大供体贡献值进行色彩标注。b,展示供体预测结果的空间分布图权重。c,来自2月龄NSC-Chimeroids(混合5)的Slide-seq数据空间分布图,按RCTD分配的细胞类型着色。d,展示细胞类型预测权重的空间分布图。e,切片#2。同图a。f,切片#2。同图b。g,Slide#2。同图c。h,Slide#2。同图d。i,放置于多电极阵列(MEA)上的代表性类器官。j,4月龄MD-NSC Chimeroid网络爆发的代表性活动图谱,其中图谱每个像素代表一个电极(左图),活动图谱中高亮电极的动作电位示例轨迹(右图)。k,显示活跃电极(139个,定义为类器官轮廓内平均放电频率>0.15次/秒的电极)在15分钟记录期间放电活动的代表性点阵图。网络爆发约在5分钟左右开始出现。l,AMPA和NMDA阻断剂(D-AP5, 150μM; DNQX 60μM)对神经元活动/网络爆发的影响(左图);4个记录的NSC-Chimeroids网络爆发活动(右图)。
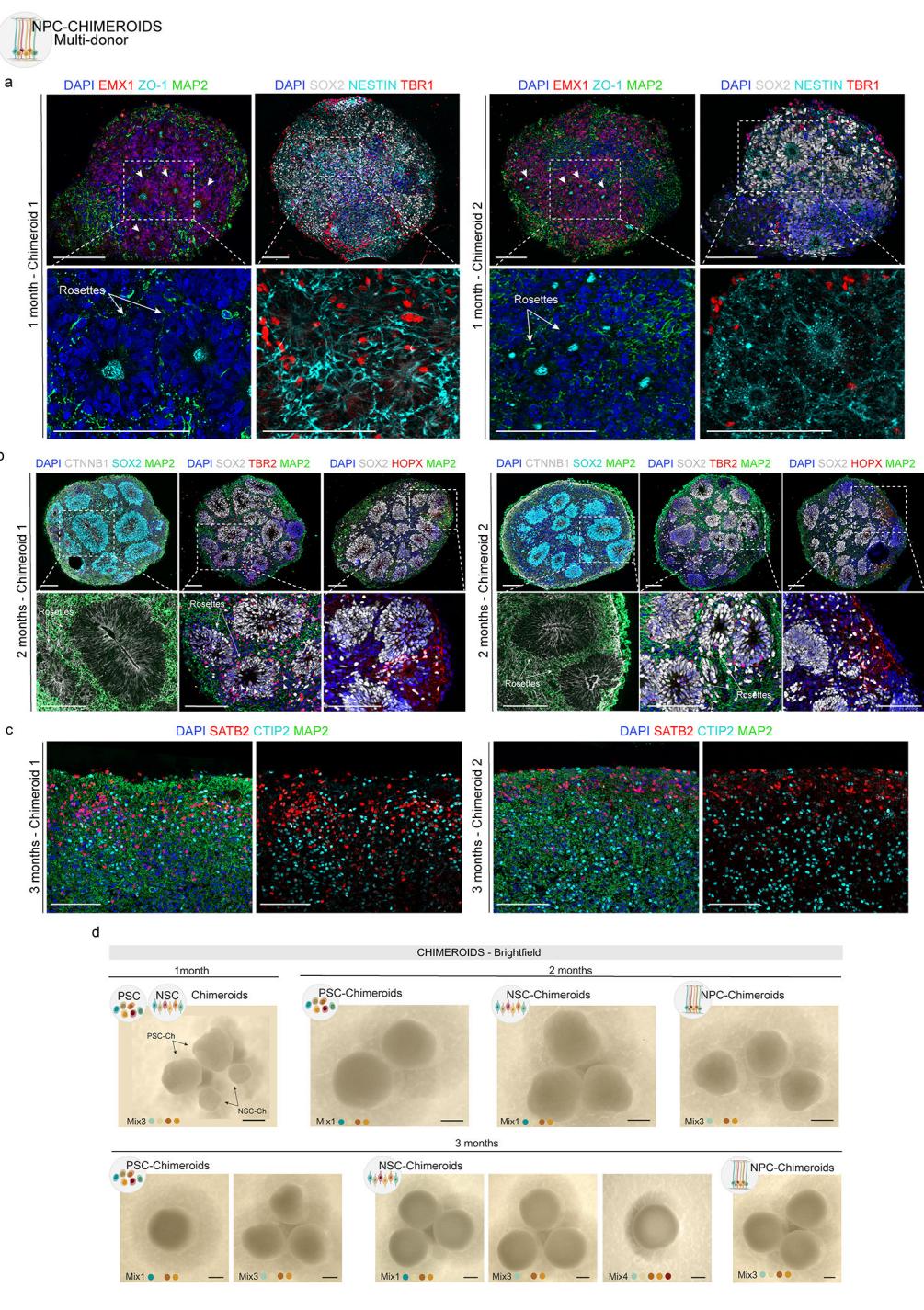
¶ 扩展数据图6. NPC-Chimeroids展现适当分化标志物。
a、1月龄NPC-Chimeroids的免疫标记显示早期祖细胞(SOX2)、皮质祖细胞(EMX1);玫瑰状结构中心由ZO-1(一种存在于放射状胶质细胞足端的紧密连接蛋白)勾勒轮廓,NESTIN信号表明神经上皮极性正确。CFuPN神经元通过TBR1标识,神经元树突通过MAP2标记。b、2月龄NPC-Chimeroids的免疫标记显示早期祖细胞(SOX2)、中间祖细胞(TBR2)和外放射状胶质细胞(HOPX)。CTNNB1标记神经玫瑰状结构中心,表明神经上皮极性正确。c、3月龄NPC-Chimeroids的免疫标记显示皮质标记物如SATB2(上层皮质神经元)和CTIP2(深层皮质神经元)。白色箭头指向神经玫瑰花结。比例尺:100 μm。d,所有方案中3个月Chimeroids的明场图像(比例尺:1 mm)。
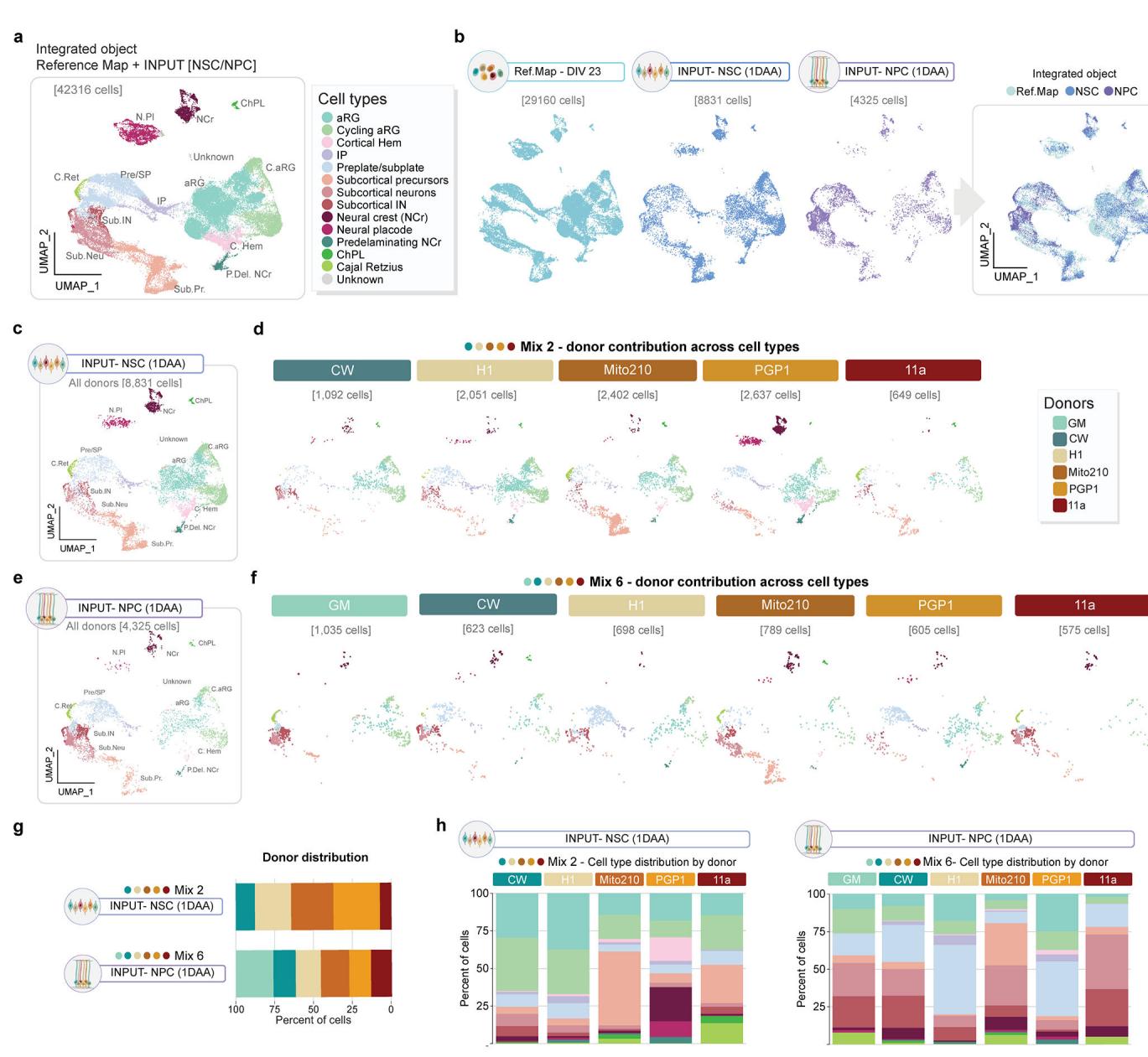
¶ 扩展数据图7. 新生嵌合体在聚集步骤中的输入由预期的细胞类型群体构成。
a, 整合数据集的 UMAP,包含来自我们 Velasco 协议类器官发育参考图谱(“参考图谱”)的 DIV23 类器官,以及聚集后 1 天的 MD-NSC 和 MD-NPC 嵌合体(输入),按注释的细胞类型进行颜色编码。�b. 按协议分割的 UMAPs。�c, MD-NSC 嵌合体(混合 2)输入的 UMAP,按注释的细胞类型进行颜色编码。�d, 按供体分割的 UMAPs。�e,MD-NPC 嵌合体(混合 6)输入的 UMAP,按注释的细胞类型进行颜色编码。�f, 按供体分割的 UMAPs。�g, 供体经过单细胞RNA测序后进行解复用。h、各供体INPUT MD-NSC与MD-NPC嵌合体中细胞类型比例的条形图。

¶ 扩展数据图 8. 单供体嵌合体展示适当的分化标记。
a、1月龄11a SD-NSC嵌合体的免疫标记显示早期祖细胞(SOX2)、皮质祖细胞(EMX1);玫瑰斑中心由ZO-1(一种存在于放射状胶质细胞足突中的紧密连接蛋白)勾勒轮廓,NESTIN与CTNNB1信号表明具有正确极性的神经上皮被早期新生CFuPN神经元包围。b、同图组a,针对 PGP1 SD-NSC 嵌合体。c,3个月 11a SD-NSC 嵌合体的免疫标记,显示皮质标记物如 SATB2(上层皮质神经元)和 CTIP2(深层皮质神经元)。d,同面板 c,针对 PGP1 SD-NSC 嵌合体。白色箭头指向神经玫瑰花结。比例尺:100 μm。
¶ 扩展数据图 9. 嵌合体跨协议和供体的比较。
a、UMAP显示细胞重叠邻域,通过Milo计算得出。红色和蓝色表示来自单供体细胞显著富集的邻域。或多供体Chimeroid。点大小表示邻域内的细胞数量,边粗细表示成对邻域间共享的细胞数量。b、蜂群图显示细胞邻域组成的变化,按这些邻域细胞类型身份分组。每个点代表一个包含50-200个具有相似基因表达谱细胞的邻域。纵轴表示邻域内单供体细胞的富集程度,正对数倍变化值表示单供体细胞多于预期,负值表示少于预期。邻域着色基于该富集程度的统计学显著性:灰色表示与随机无显著差异;红色表示显著过度富集;蓝色表示显著低度富集。c-d、火山图分别显示MD与SD-NSC Chimeroid方案间整体及各供体(c)、各主要细胞类型(d)的差异表达基因。正log2倍变化表示在SD方案中表达更高。e、相关性散点图比较MD-NSC Chimeroid中每对供体间差异表达基因与SD-NSC Chimeroid中相同供体对间的差异。x轴和y轴分别显示MD和SD中的log2倍变化。点大小和颜色分别表示在MD和SD中的统计学显著性。f、热图显示MD-NSC Chimeroid方案中各供体(列)与SD-NSC Chimeroid方案中各供体(行)间log2倍变化的绝对值均值。数值越低表明越相似;每个供体的样本在另一方案中与同供体样本转录组相似度最高。g、Aitchison距离衡量各方案内重复样本间细胞类型组成的差异度,按批次内和批次间比较分组,且仅限源自PGP1和Mito210供体的细胞(因仅这两名供体存在于本研究所涉所有类器官/Chimeroid方案)。(n=23个PGP1、23个Mito210和10个胎儿样本;箱线图显示上下四分位数及中位数,须线显示最近铰链1.5倍四分位距内的最高/最低值)。三个胎儿皮质数据集内样本间的细胞类型组成差异亦展示于此,表明个体间自然变异。虚线代表各胎儿数据集内样本间平均距离20,22,23。
¶ 扩展数据图 10. Chimeroids展现出与单供体类器官及胎儿组织相似的细胞类型复杂性。
等级-等级超几何重叠图(RR-HO)将多供体嵌合体中细胞类型的表达特征与以下数据进行对比:单供体嵌合体中的所有细胞类型、我们参考图谱中Velasco方案类器官发育的皮质类器官、或内源性人类胎儿组织²�。水平轴代表多供体神经干细胞嵌合体细胞类型相较于其他所有嵌合体细胞的标记基因列表,按从最显著上调至最显著下调的顺序排列;垂直轴则对应单供体神经干细胞嵌合体、参考图谱类器官或人类胎儿组织中类似排序的标记基因列表。胎儿细胞。特定位置的颜色表示截至该点的基因列表重叠的显著性(负对数p值),通过Fisher精确检验计算得出。左下和右上象限的高显著性(即红色)表明定义被比较细胞类型的表达谱之间存在高度一致性。a、b、c、d和e代表所分析的不同细胞类型。f、RR-HO图的解释性示意图。
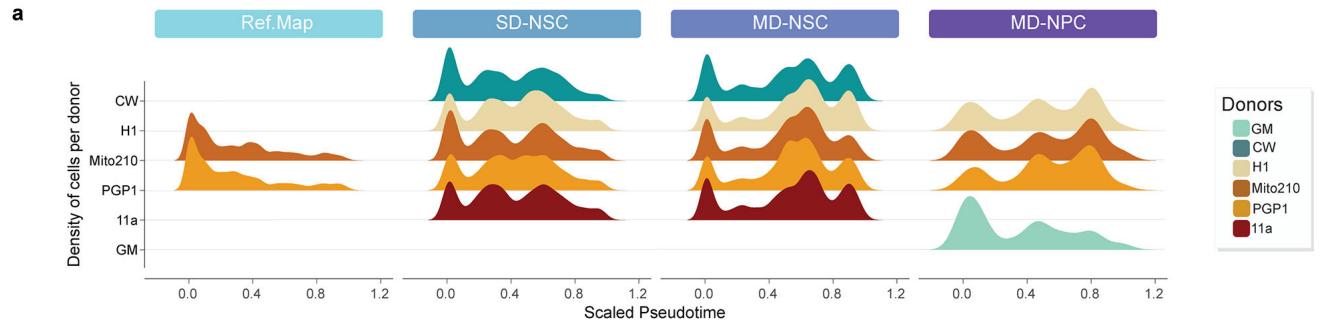
¶ 扩展数据图11. 嵌合体在不同供体和方案间展现出相似的发育轨迹与代谢特征。
a, 密度图显示各类器官/嵌合体方案中每位供体的缩放伪时间分布情况。伪时间使用Monocle3独立计算每个方案,并将各数据集中的aRG细胞设为根细胞。b, 在PGP1/Mito210细胞中采用线性混合效应模型(使用lme4的lmer函数)计算的各细胞类型/供体/嵌合体的糖酵解模块得分,其中将供体作为随机效应(n=4个方案共40个重复;箱形图显示上下四分位数与中位数,须线表示在最近铰链的1.5倍四分位距(IQR)内的最高/最低值)。P值是通过单尾F检验生成的,该检验比较了包含与不包含“方案”作为协变量的模型。图c-d,糖酵解基因集的表达在供体间(来自n=45个供体/嵌合体的12,887个细胞)和方案间(来自n=40个供体/嵌合体和类器官的20,425个细胞)具有相似性。小提琴图展示了MSigDB标志性糖酵解基因集在细胞类型、供体和方案中的模块评分;箱线图显示上、下四分位数和中位数,须线表示最近铰链1.5倍四分位距(IQR)内的最高/最低值。模块评分使用Seurat的addModuleScores函数计算。
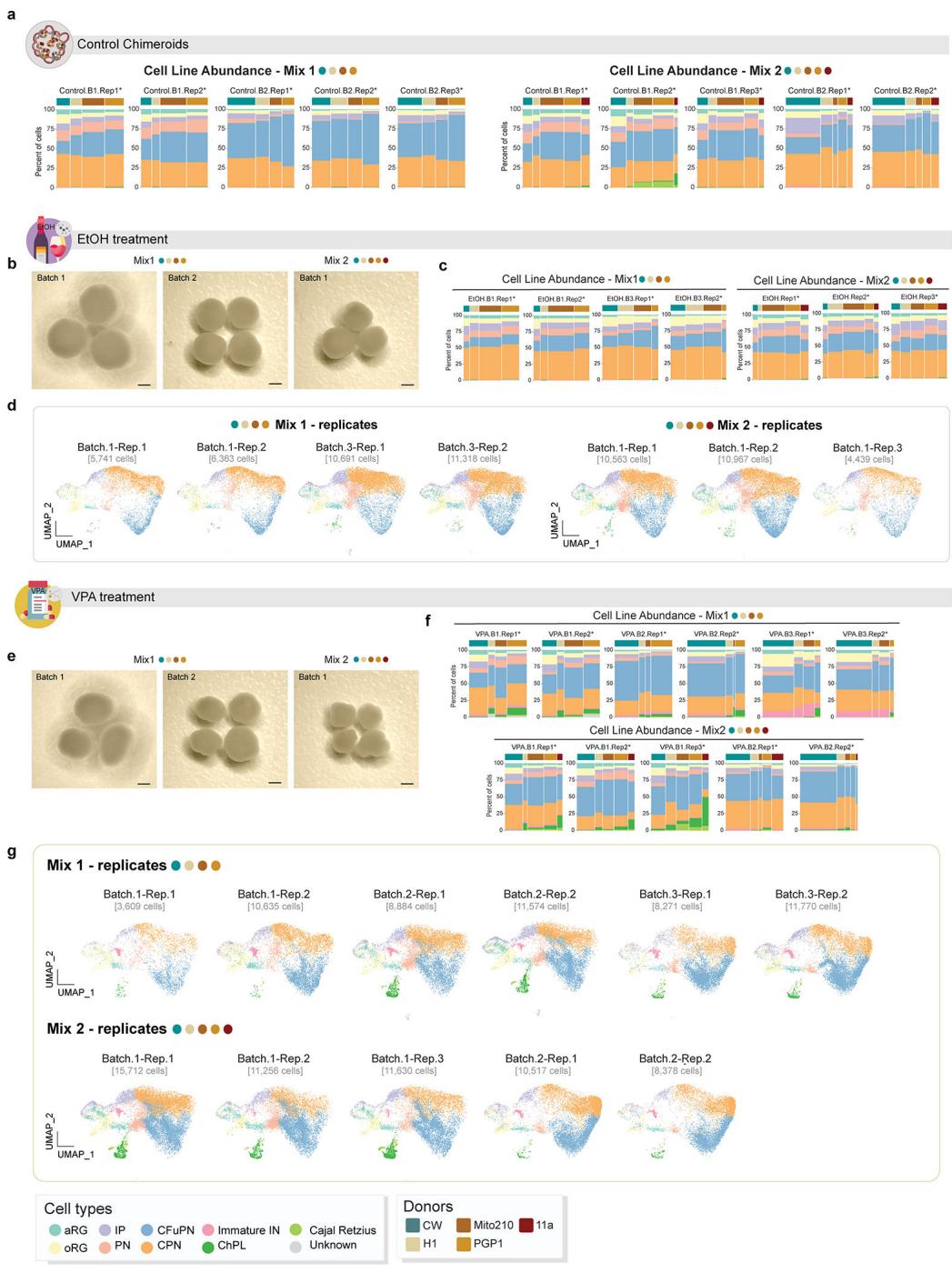
¶ 扩展数据图12. VPA和乙醇处理差异影响NSC-Chimeroids中的细胞类型组成。
a、堆积条形图显示对照组Chimeroids的细胞类型和供体构成;每个条形宽度对应Mix 1(4名供体,左图)和Mix 2(5名供体,右图)中指定供体的比例。b、乙醇处理条件下培养3个月的整体皮质NSC-Chimeroids明场图像。比例尺:1毫米。c、堆积条形图显示乙醇处理组Chimeroids的细胞类型和供体构成;每个条形宽度对应Mix 1(4名供体,左图)中指定供体的比例,面板)和混合2(5名供体,右图)。d、按混合组和重复样本分列的乙醇处理NSC嵌合体UMAP图谱。e、VPA处理条件下培养3个月的完整皮质MD-NSC嵌合体明场图像。比例尺:1毫米。f、显示乙醇处理嵌合体细胞类型与供体组成的堆叠条形图;各条形宽度对应混合1(4名供体,上图)与混合2(5名供体,下图)中指定供体的占比。g、按混合组和重复样本分列的VPA处理NSC嵌合体UMAP图谱。
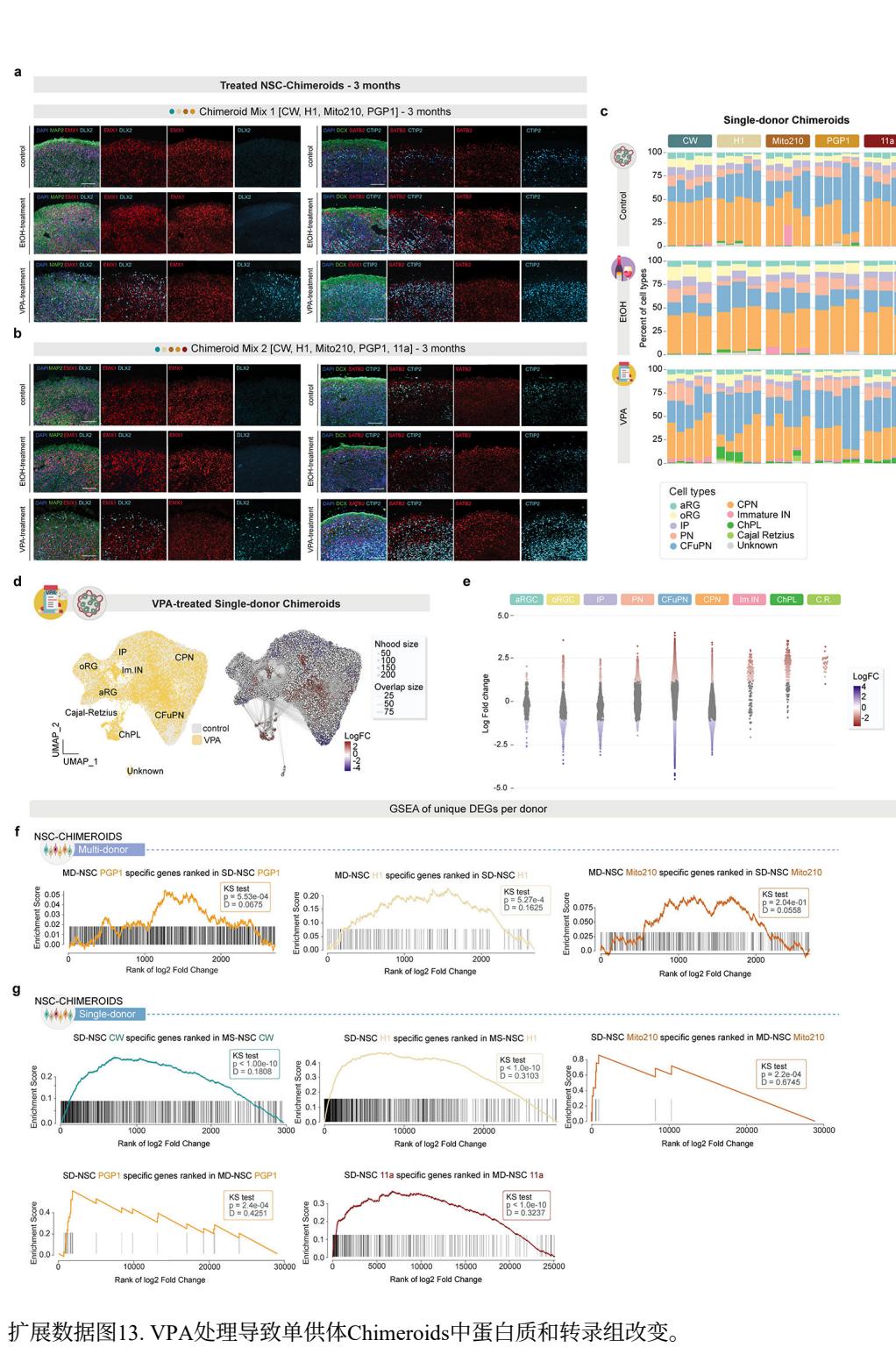
a,多供体NSC-Chimeroids的免疫标记(a,混合1,上图;b,混合2,下图)。左图:MAP2(神经元树突)、EMX1(皮质祖细胞)和DLX2(GABA能细胞)。右图:DCX(迁移神经元)、SATB2(上层皮质神经元)和CTIP2(深层皮质神经元)。比例尺:100μm。c,堆叠条形图显示对照和处理单供体NSC-Chimeroids的细胞类型组成。d,左图:VPA处理(黄色)与对照(灰色)单供体Chimeroids的细胞类型特异性变化。右图:UMAP显示通过Milo计算得到的细胞重叠邻域。红色和蓝色分别表示VPA处理细胞或对照细胞显著富集的邻域。点大小表示邻域中的细胞数量,边粗细表示邻域对之间共享的细胞数量。e,蜂群图显示单供体Chimeroids中细胞邻域组成对VPA处理的响应变化,按邻域细胞类型身份分组。每个点代表一个包含50-200个具有相似基因表达谱细胞的邻域。纵轴表示邻域内VPA处理细胞的富集程度,正对数倍变化值表示VPA处理细胞多于预期,负值表示少于预期。邻域颜色基于富集的统计学显著性:灰色表示与随机无显著差异;红色表示显著过度富集;蓝色表示显著低度富集。若某细胞类型中大多数邻域集体上移或下移,则提示VPA处理Chimeroids中该细胞类型整体增加或减少。同时存在过度富集和低度富集长尾分布的细胞类型,可能发生处理诱导的表达谱改变而不一定伴随数量变化。f,MD-NSC Chimeroids供体特异性基因在对应单供体数据集上的GSEA排序。g,SD-NSC Chimeroids供体特异性基因在对应多供体数据集上的GSEA排序(下图)。P值通过双侧Kolmogrov-Smirnov检验计算。
¶ 补充材料
请参考PubMed Central上的网络版本获取补充材料。
¶ 致谢
我们感谢Juliana R. Brown(来自P.A.实验室)对稿件编辑提出的意见与协助,感谢Lila L. Lyons、Noah Kozub和Sarah Tropp提供的卓越技术支持,并感谢Arlotta实验室全体成员进行的讨论;感谢B. Cohen(麦克莱恩医院)提供Mito210 iPSC细胞系;感谢G. Church(哈佛大学)提供PGP1 iPSC细胞系;感谢M. Talkowski(麻省总医院)提供GM08330 iPSC细胞系;感谢Broad基因组学平台完成测序工作;感谢Steve McCarroll(哈佛医学院)提供Census-seq技术方案。我们还要感谢Bertrand Yeung(Curio Biosciences)在Curioseeker数据预处理方面给予的支持。示意图中的部分元素改编自Biorender。本研究获得了以下基金支持:斯坦利精神病学研究中心授予P.A.、R.N.和J.Z.L.的资助,麻省理工学院与哈佛大学博德研究所,美国国立卫生研究院(授予P.A.的P50-MH094271和RF1-MH123977,授予P.A.和J.Z.L.的R01-MH112940,以及授予R.N.的U01-MH115727),以及克拉曼细胞观测站(A.R.)。
¶ 数据可用性
单细胞RNA测序的读取水平数据已存入synapse.org,项目编号为SynID syn52132869,而计数水平数据和元数据则保存在
¶ 参考文献
Paulsen B 等。自闭症基因汇聚于共享神经元类别的异步发育。《自然》602, 268–273 (2022)。[PubMed: 35110736] 2. Pizzo L 等。遗传背景中的罕见变异可调控携带疾病相关变异个体的认知与发育表型。《基因医学》21, 816–825 (2019)。[PubMed: 30190612] 3. Ford LC 等。基于人群的体外定量方法评估个体对化学混合物反应的差异性。《毒理学》10, 441 (2022)。[PubMed: 36006120] 4. Germain P-L 与 Testa G。驾驭人类遗传变异性:转录组荟萃分析指导iPSC疾病建模的实验设计与解读。《干细胞报告》8, 1784–1796 (2017)。 5. Tegtmeyer M 等。通过高维表型分析界定细胞形态的遗传基础。bioRxiv 2023.01.09.522731 (2023) doi:10.1101/2023.01.09.522731。 6. Cederquist GY 等。人多能干细胞多重平台界定自闭症相关基因的分子与功能亚类。《细胞·干细胞》27, 35–49.e6 (2020)。[PubMed: 32619517] 7. Cuomo ASE 等。分化iPS细胞的单细胞RNA测序揭示基因表达的动态遗传效应。《自然·通讯》11, 810 (2020)。[PubMed: 32041960] 8. Jerber J 等。多巴胺能神经元分化过程的人群规模单细胞RNA-seq分析。《自然·遗传学》53, 304–312 (2021)。[PubMed: 33664506] 9. Limone F 等。通过Ngn2表达与发育信号耦合高效生成下诱导运动神经元。《细胞报告》111896 (2023) doi:10.1016/j.celrep.2022.111896。[PubMed:36596304] 10. Mitchell JM 等。利用“细胞村庄”绘制遗传对细胞表型的影响。Biorxiv 2020.06.29.174383 (2020) doi:10.1101/2020.06.29.174383。 11. Wells MF 等。神经祖细胞村庄揭示基因表达与病毒易感性的自然变异。《细胞·干细胞》30, 312–332.e13 (2023)。[PubMed: 36796362]12. Wozniak JR, Riley EP 与 Charness ME。胎儿酒精谱系障碍的临床表现、诊断与管理。《柳叶刀·神经病学》18, 760–770 (2018)。 13. Bjørk M-H 等。产前抗癫痫药物暴露与自闭症及智力残疾风险的关联。《美国医学会杂志·神经病学》79, 672–681 (2022)。[PubMed: 35639399] 14.Christensen J 等。产内丙戊酸钠暴露与自闭症谱系障碍及儿童自闭症风险。《美国医学会杂志》309, 1696–1703 (2013)。[PubMed: 23613074] 15. Neavin DR 等。用于人群规模hiPSC研究的“培养皿村庄”模型系统。《自然·通讯》14, 3240 (2023)。[PubMed: 37296104] 16. Villa CE 等。CHD8单倍体不足将自闭症与兴奋抑制通路的瞬时改变相关联。《细胞报告》39, 110615 (2022)。[PubMed: 35385734] 17. Warren CR 与 Cowan CA。培养皿中的人类:iPSC与群体遗传学。《细胞生物学趋势》28, 46–57 (2018)。[PubMed: 29054332] 18. Velasco S 等。个体脑类器官可重复形成人脑皮层细胞多样性。《自然》570, 523–527 (2019)。[PubMed: 31168097] 19. Kang HM 等。利用自然遗传变异进行微滴单细胞RNA多重测序。《自然·生物技术》36, 89–94 (2018)。[PubMed: 29227470]
Uzquiano A 等。类器官中细胞类别特性的正确获取使得能够定义人类大脑皮层的命运规范程序。《细胞》185, 3770–3788.e27 (2022)。[PubMed: 36179669] 21. Dann E 等。使用k近邻图对单细胞数据进行差异丰度检测。《自然·生物技术》40, 245–253 (2022)。[PubMed: 34594043]22. Trevino AE 等。单细胞分辨率下发育中人类大脑皮层的染色质和基因调控动态。《细胞》184, 5053–5069.e23 (2021)。[PubMed: 34390642] 23. Polioudakis D 等。人类妊娠中期新皮质发育的单细胞转录图谱。《神经元》103, 785–801.e8 (2019)。[PubMed: 31303374] 24. Cahill KM 等。采用更新后的秩秩超几何重叠方法改进一致性与差异性基因表达特征的识别。《科学报告》8, 9588 (2018)。[PubMed: 29942049] 25. Stuart T 等。单细胞数据的全面整合。《细胞》177, 1888–1902.e21 (2019)。[PubMed: 31178118] 26. Cao J 等。哺乳动物器官发生的单细胞转录图谱。《自然》566, 496–502 (2019)。[PubMed: 30787437] 27. Manno GL 等。单细胞的RNA速率。《自然》560, 494–498 (2018)。[PubMed: 30089906] 28. Alfonso-Loeches S 等。酒精对成年及发育中大脑作用的分子与行为学研究。《临床实验室科学评论》48, 19–47 (2011)。[PubMed: 21657944] 29. Arzua T 等。利用人诱导多能干细胞衍生的三维脑类器官模拟酒精诱导的神经毒性。《转化精神病学》10, 347 (2020)。 30. Carpita B 等。自闭症谱系障碍与胎儿酒精谱系障碍:文献综述。《脑科学》12, 792 (2022)。[PubMed: 35741677] 31. Charness ME。胎儿酒精谱系障碍:五十年从认知到洞察。《酒精研究》 : 《当代评论》42, 05 (2022)。 32. Eberhart JK 等。胎儿酒精谱系障碍的遗传学。《酒精临床与实验研究》40, 1154–65 (2016)。[PubMed: 27122355] 33. Granato A 等。酒精与发育中大脑:神经元死亡机制与存续细胞的适应性改变。《国际分子科学杂志》19, 2992 (2018)。[PubMed: 30274375] 34. Marguet F 等。酒精暴露人类胎儿中少突胶质细胞谱系严重受损。《神经病理学通讯》10, 74 (2022)。[PubMed: 35568959] 35. Streissguth AP等。酗酒母亲双胎的胎儿酒精综合征:诊断与智商的一致性。《美国医学遗传学杂志》47, 857–861 (1993)。[PubMed: 8279483] 36. Sulik KK 等。胎儿酒精综合征:小鼠模型中的胚胎发生。
科学 214, 936–938 (1981). [PubMed: 6795717] 37. 孟强 等. 人前脑类器官揭示丙戊酸暴露与自闭症风险之间的关联. 转化精神病学 12, 130 (2022). [PubMed: 35351869] 38. Church GM 个人基因组计划. 分子系统生物学 1, 2005.0030–2005.0030 (2005). 39. Sheridan SD 等. FMR1基因的表观遗传学特征与神经发育异常
在人类诱导多能干细胞模型中的脆性X染色体综合征研究。《公共科学图书馆·综合》6卷,e26203(2011年)。[PubMed: 22022567] 40. Sugathan A 等。CHD8在神经祖细胞中调控与自闭症谱系障碍相关的神经发育通路。《美国国家科学院院刊》111卷,E4468–E4477(2014年)。[PubMed: 25294932] 41. Thomson JA 等。源自人类囊胚的胚胎干细胞系。《科学》282卷,1145–1147(1998年)。[PubMed: 9804556] 42. Boulting GL 等。一组功能特征明确的人类诱导多能干细胞测试集。《自然·生物技术》29卷,279–286(2011年)。[PubMed: 21293464]43. Schindelin J 等。Fiji:生物图像分析的开源平台。《自然·方法》9卷,676–682(2012年)。[PubMed: 22743772]
- Goodchild SJ 等。《选择性NaV1.6及双靶点NaV1.6/NaV1.2通道抑制剂抑制离体兴奋性神经元活动的分子药理学研究》。ACS化学神经科学 15, 1169–1184 (2024)。[PubMed: 38359277] 45. Zheng GXY 等。《单细胞的大规模并行数字化转录本分析》。自然·通讯 8, 14049 (2017)。[PubMed: 28091601] 46. Danecek P 等。《SAMtools与BCFtools的十二年发展历程》。巨型科学 10,giab008 (2021)。[PubMed: 33590861] 47. 陈烨、Lun ATL & Smyth GK《从测序片段到基因再到通路:使用Rsubread与edgeR准似然流程的RNA-Seq差异表达分析》。F1000研究 5, 1438 (2016)。[PubMed: 27508061] 48. McCarthy DJ、陈烨 & Smyth GK《基于生物学变异的多因子RNA-Seq实验差异表达分析》。核酸研究 40, 4288–4297 (2012)。[PubMed: 22287627] 49. Robinson MD、McCarthy DJ & Smyth GK《edgeR:用于数字基因表达数据差异表达分析的Bioconductor软件包》。生物信息学 26, 139–140 (2010)。[PubMed: 19910308] 50. Cable DM、Murray E、Zou LS等。《空间转录组中细胞类型混合物的鲁棒分解》。自然·生物技术 40, 517–526 (2022)。10.1038/s41587-021-00830-w [PubMed: 33603203]

Cell type abundance
图1. NSC-Chimeroids 在细胞类别中保持供体代表性。�a, 在1个月(mo)的皮质PSC-Chimeroids中对MAP2、EMX1和NESTIN进行免疫标记。比例尺: 500 μm (整体) 和 250 μm (放大)。�b, 在3个月PSC-Chimeroids中的供体贡献(去多重单细胞RNA测序), 按供体颜色编码。�c, 神经干细胞(NSC)-Chimeroid方案的示意图。�d, 在3个月NSC-Chimeroids中的供体贡献, 如c所示。�e, 1个月(比例尺: 100 μm)和3个月皮质NSC-Chimeroids的免疫标记(比例尺: 500 μm)。�f, 2个月MD-NSC Chimeroids (Mix 5)的Slide-seq分析, 按RCTD分配的细胞类型着色(上面板)和通过Census-seq的供体贡献着色(下面板)。�g, 整合NSC Chimeroids的UMAP(显示每个数据集的总细胞数), 按注释的细胞类型(上面板)和供体系颜色编码, 以及定量
供体贡献(下图)。h,按供体拆分的两个不同混合组(混合1和混合2)的UMAP图。i,按供体分离的NSC-Chimeroids细胞类型比例条形图。实心条:中位数;误差条表示重复样本的上四分位数与下四分位数(CW、H1、Mito210和PGP1的n=7;11a的n=3)。j,混合1和混合2中各供体细胞类型比例的堆积条形图。
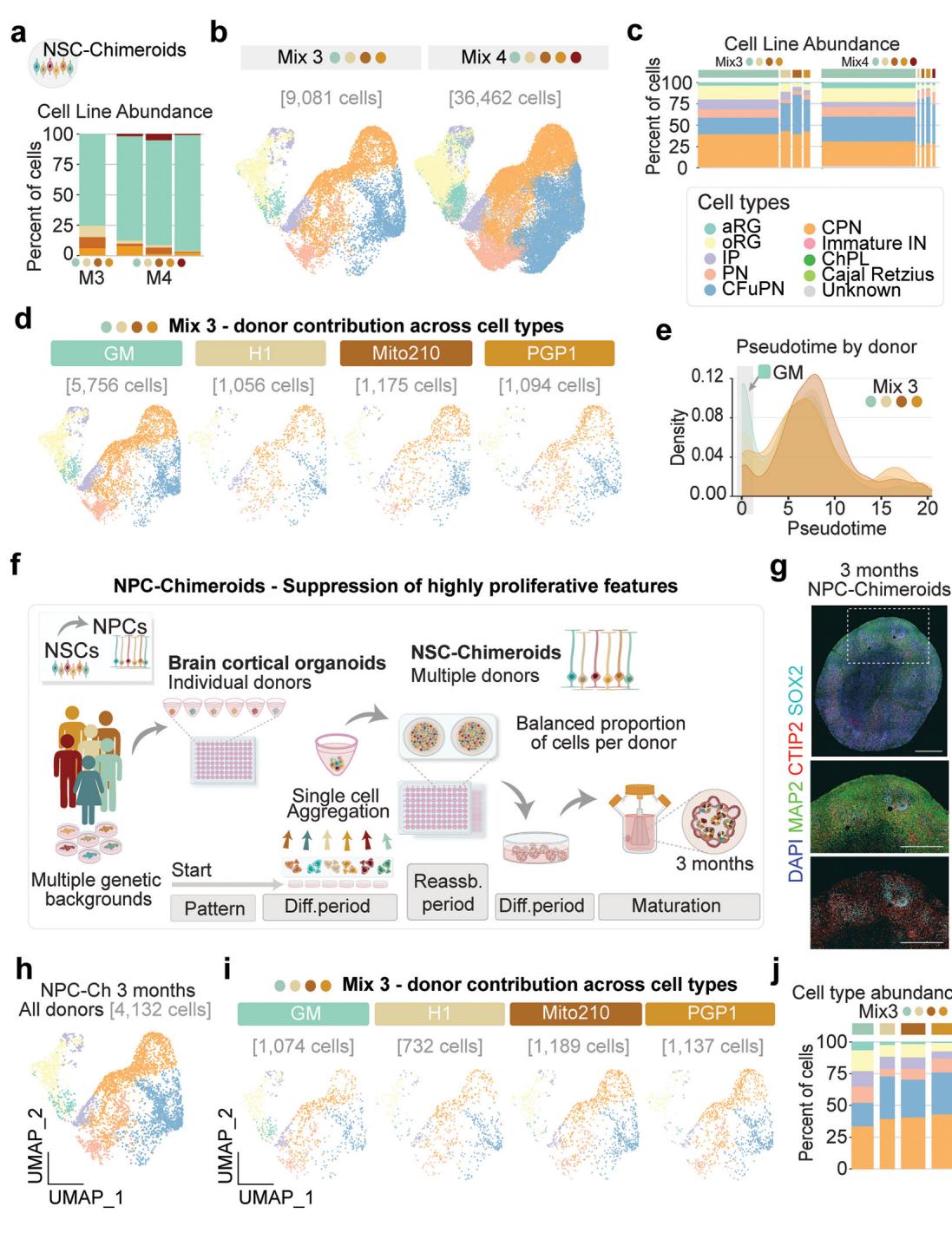
图2. NSC和NPC嵌合体控制起始多能干细胞的过度增殖状态。
a,通过单细胞RNA-seq分析并针对Mix 3和Mix 4按供体进行分离的3月龄NSC-Chimeroids。b,Mix 3和Mix 4的3月龄NSC-Chimeroid UMAP图(每个数据集的总细胞数)。c,显示细胞类型和供体组成的条形图;条形宽度对应供体比例。d,按供体分列的Mix 3 UMAP图。e,通过Monocle3以所有循环细胞为根计算的各细胞系伪时序密度图。f,NPC-Chimeroid方案示意图。NPCs:神经祖细胞。g,免疫组织化学分析
显示SOX2、CTIP2和MAP2染色的3月龄NPC-Chimeroids。比例尺:500 μm。h-i. 整合后(h)及按供体拆分(i)的NPC-Chimeroids UMAP可视化(展示各数据集总细胞数)。j. 细胞类型与供体组成的条形图。

图3. 嵌合类脑器官具有可重复性并展现适宜的细胞类型组成 a,皮质类器官中细胞群体的示意图。b,参考图谱类器官20、NSC-嵌合类器官、单供体(SD)NSC-嵌合类器官及NPC-嵌合类器官中主要细胞类型的标记基因表达。c,人胎儿皮质细胞类型(43,935个细胞,n=4次重复)与参考图谱类器官(134,282个细胞,n=21次重复,7个批次)、NSC-嵌合类器官(95,123个细胞,n=10次重复,2个批次)、SD-NSC-嵌合类器官(48,119个细胞,n=25次重复,2个批次)及NPC-嵌合类器官(3,711个细胞,n=2次重复)中对应细胞类型的标准化标记基因表达皮尔逊相关系数。箱线:中位数及上下四分位数;须线:最近铰链1.5倍四分位距内的最高/最低值。d,通过秩秩超几何重叠分析评估MD-NSC嵌合类器官与参考图谱类器官或内源性胎儿组织中CFuPN表达特征的一致性(另见扩展数据图10f)。e,按类器官方案分组的各供体细胞系不同细胞类型平均丰度。星号表示与多供体NSC嵌合类器官中同一供体相比丰度发生显著改变的细胞类型(基于负二项模型的edgeR双侧拟然比F检验)(0.05 > * > 0.005 > ** > 0.0005 > ***)。f,各方案内供体匹配重复间以及MD-NSC嵌合类器官与其他各方案间的细胞类型组成相似性(Aitchison距离)(n=58次重复,涵盖4种方案和12个批次)。箱体:中位数及上下四分位数;须线:最近铰链1.5倍四分位距内的最高/最低值。图中同时展示了三个人类胎儿皮质内源性数据集20,22,23的数值与平均值(虚线)。
比较(总计,n=16个样本)。g,使用两种不同参考数据集对嵌合体细胞进行的细胞类型注释:参考文献。类器官和人类胎儿皮层内源性细胞20,22,23。h,各主要细胞类型在不同类器官/嵌合体方案中的标准化拟时序分布。下方示意图展示各细胞类型的“时序性”出现规律。i,通过velocyto和scVelo分别对MD-(左)和SD-(右)NSC嵌合体计算的RNA速率。
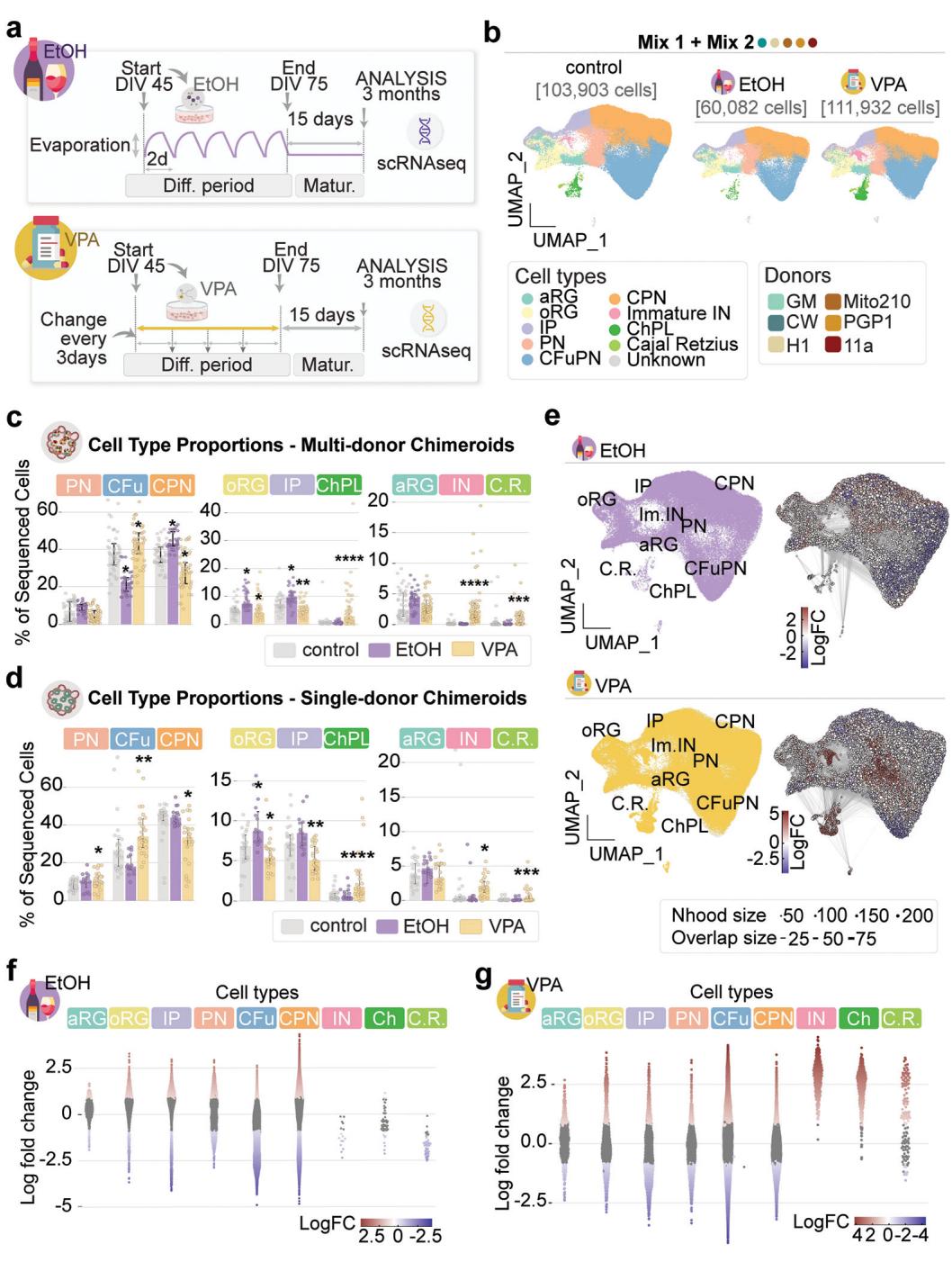
图4. NSC-Chimeroids模型处理特异性改变 a, 方案示意图。 b, 按注释细胞类型着色的整合UMAP图,用于对照和处理后的Chimeroids。 c, 细胞类型比例的条形图,显示对照MD-NSC Chimeroids中的情况:对照(灰色,n=45个样本来自10个Chimeroids)、EtOH处理(紫色,n=31个样本来自7个Chimeroids)或VPA处理(黄色,n=49个样本来自11个Chimeroids)。实心条:中位数,误差条:上四分位数和下四分位数。显著性检验:比较负二项广义线性模型的单侧F检验。FDR校正p值:* - <0.1;** - <0.01;*** - <0.001。 d. SD-NSC中细胞类型比例的变化
来自相应细胞系(对照、乙醇处理和VPA处理的样本量分别为n=25、15和25)的嵌合体类器官,如图c所示。e,左图:UMAP显示对照MD-嵌合体类器官(灰色)与VPA处理(黄色)和乙醇处理(紫色)的MD-嵌合体类器官细胞分布。右图:UMAP显示通过Milo计算得到的细胞重叠邻域。红色和蓝色分别表示乙醇/VPA处理组细胞或对照组细胞显著富集的邻域。点大小表示邻域内细胞数量,边线粗细表示邻域对之间的共享细胞数量。f-g,蜂群图显示乙醇和VPA处理后细胞邻域组成的变化,按邻域细胞类型特征分组。每个点代表一个包含50-200个具有相似基因表达谱细胞的邻域。纵轴表示处理细胞在邻域内的富集程度:正对数倍率变化表示处理细胞多于预期,负值表示少于预期。邻域颜色编码代表富集统计显著性(通过Milo的testNhoods函数使用准似然F检验计算):灰色表示与随机无显著差异;红色表示显著过富集;蓝色表示显著低富集。
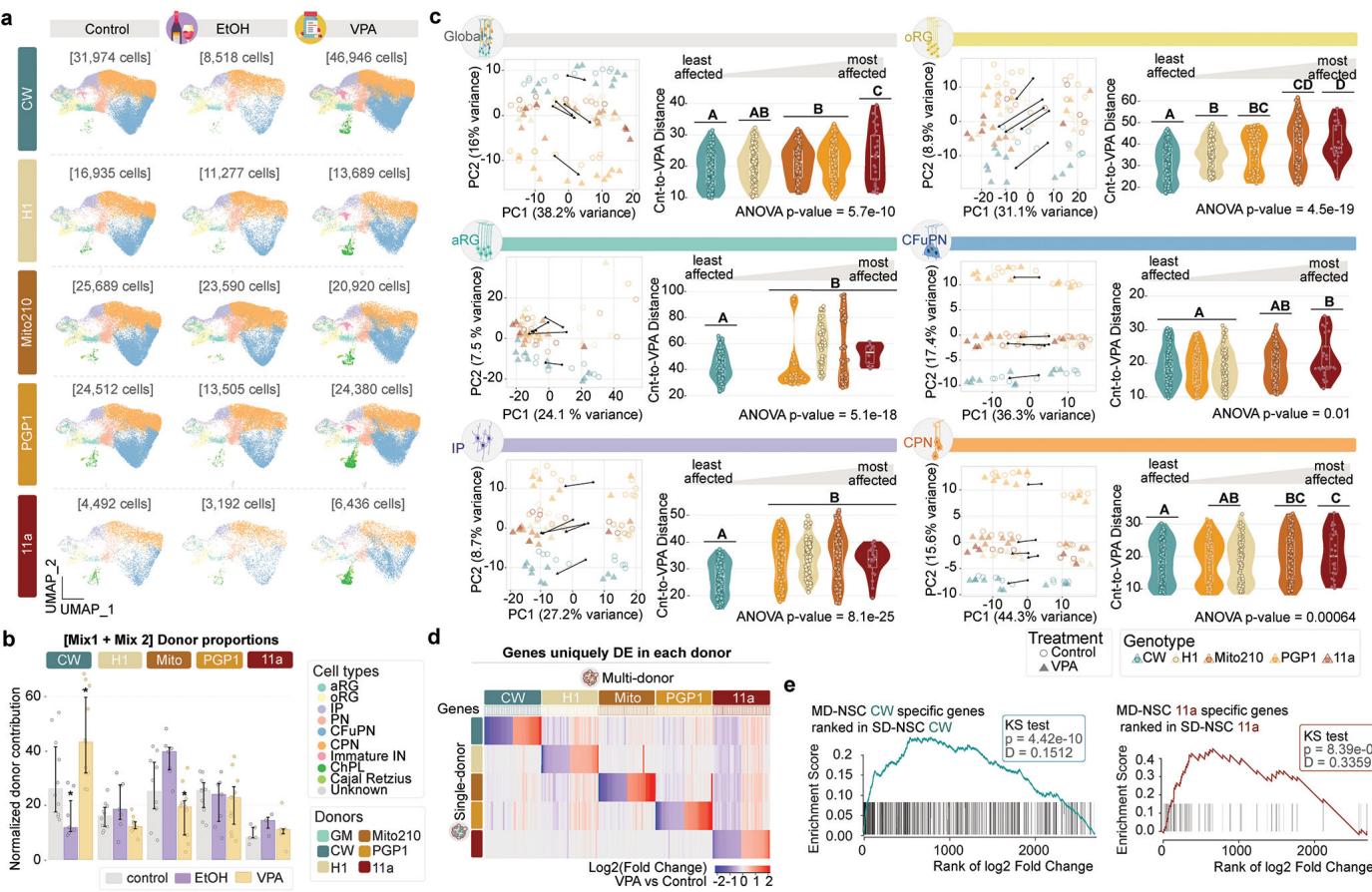
图5. NSC嵌合体揭示供体特异性易感差异。a、按供体拆分并经细胞类型着色的对照组、EtOH处理组和VPA处理组嵌合体UMAP图谱。b、对照组NSC嵌合体(灰色,n=10次重复)及EtOH(n=7次)或VPA(n=11次)处理后的标准化供体比例条形图。Y轴表示每个嵌合体中测量的供体丰度与混合样本中所有供体均等表达时的预期丰度之比。实心条:中位数;误差条:上下四分位数。显著性检验:对每个供体的细胞计数应用负二项广义混合效应模型进行单侧F检验。FDR校正p值:* - <0.1;** - <0.01;*** - <0.001(参见方法)。c、对VPA处理组(三角形)和未处理组(圆形)NSC嵌合体各细胞簇基因表达矩阵进行主成分分析,按供体(颜色标示)和重复样本进行伪批量处理,分析涵盖所有细胞(左上,n=94)及按细胞类型细分样本(oRG、aRG、CFuPN、IP和CPN分别对应n=85、70、94、88、94)。对应右侧面板:小提琴图展示各供体经处理与未处理伪批量数据点在PCA空间中的成对欧氏距离。箱线:中位数及上下四分位数;须线:最近铰链1.5倍四分位距内的最高/最低值。距离越大表明VPA处理引发的表达谱变化越显著。显著性检验:方差分析(ANOVA)及后续双尾Tukey事后配对检验。d、VPA处理MD-NSC嵌合体中供体特异性差异表达基因热图。e, 供体特异性差异表达VPA处理MD-NSC嵌合体的基因集富集分析(GSEA),基于对应的SD-NSC数据集排序。P值通过双侧柯尔莫哥洛夫-斯米尔诺夫检验计算。